Genetyka molekularna
Ekspresja informacji genetycznej
Wyjaśnisz, czym jest kod genetyczny i przedstawicz jego cechy.
Opiszesz proces transkrypcji, z uwzględnieniem roli polimerazy RNA.
Opiszesz proces obróbki potranskrypcyjnej u organizmów eukariotycznych.
Opiszesz proces translacji i przedstawisz znaczenie modyfikacji potranslacyjnej białek.
Porównasz przebieg ekspresji informacji genetycznej w komórce prokariotycznej i eukariotycznej.
Ekspresja informacji genetycznej (ekspresja genów) to szereg procesów umożliwiających odczytanie „instrukcji” budowy białka zapisanej w DNA. Rozpoczyna się od transkrypcji (czyli „przepisania”) informacji genetycznej w jądrze komórkowym na mRNA. Następnie informacja genetyczna w postaci mRNA zostaje przeniesiona do cytoplazmy, gdzie na rybosomach na jej podstawie zachodzi translacja, czyli biosynteza białka.
Kod genetyczny
Kod genetyczny określa rodzaj i kolejność aminokwasów w łańcuchu polipeptydowym.
Rodzaj i kolejność aminokwasów są wyznaczane przez sekwencję nukleotydów w DNA, na podstawie którego syntetyzowana jest nić mRNA. Synteza mRNA, czyli transkrypcja odbywa się na zasadzie komplementarności: cytozyna (C) jest komplementarna do guaniny (G), a adenina (A) do uracylu (U). Następnie na podstawie RNA syntetyzowany jest łańcuch polipeptydowy.
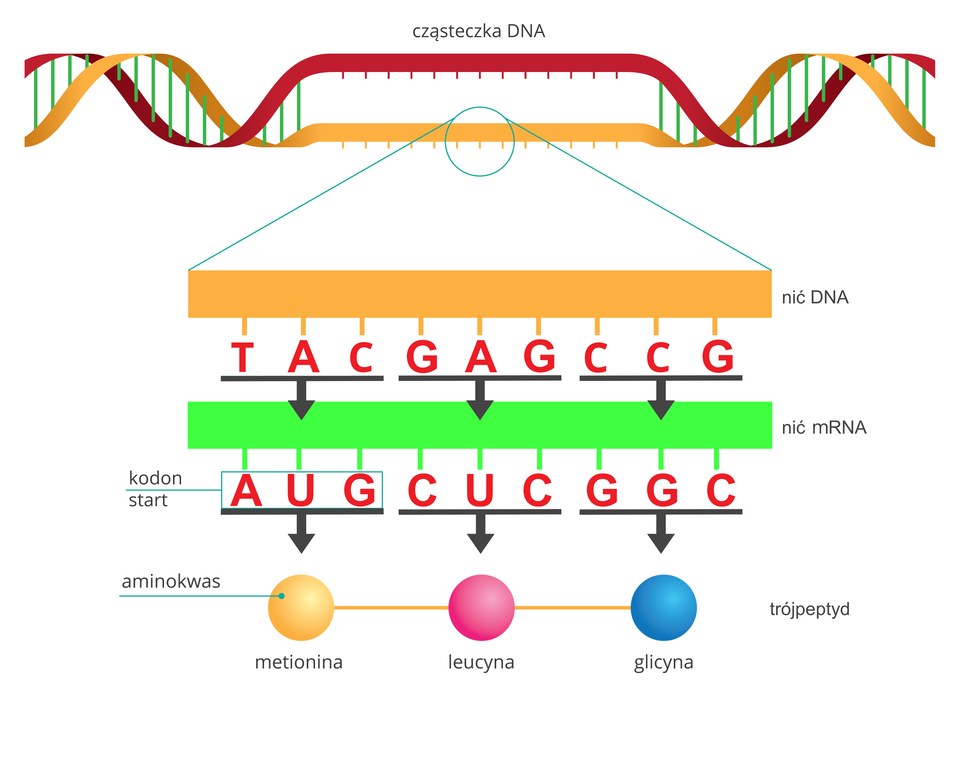
Kod genetyczny jest zapisany w postaci trójek nukleotydów RNA, zwanych kodonami. Zależności między kodonami i aminokwasami, które one kodują zestawione są w tabelach kodu genetycznego. W większości z nich aminokwasy zapisywane są skrótami jedno- lub trójliterowymi. Na przykład alanina może być w skrócie zapisana jako Ala lub A, a arginina jako Arg lub R.
Składa się ona z poziomych i pionowych kolumn. Odczytywanie zaczyna się zawsze od lewej strony, w pozycji „1 nukleotyd”. Występują tu cztery wiersze oznaczone: U (uracyl), C (cytozyna), A (adenina), G (guanina) – są to pierwsze litery kodonu odpowiadającego za dany aminokwas.
Drugi nukleotyd w kodonie znajduje się w górnej osi tabeli, oznaczonej jako „2 nukleotyd”. Wiersze z kolumny „1 nukleotyd” przecinają się z kolumnami zawierającymi drugi nukleotyd uszeregowanymi w kolejności: U, C, A, G, tworząc duży kwadrat z czterema różnymi sekwencjami.
Trzeci nukleotyd odczytywany jest z kolumny „3 nukleotyd”, gdzie nukleotydy ułożone są w kolejności U, C, A, G. Znalezienie trzeciego nukleotydu pozwala na skompletowanie wszystkich nukleotydów w kodonie i odczytanie przypisanego do danego kodonu aminokwasu bądź też sygnału START (wyznaczającego pierwszy kodon, od którego zaczyna się synteza każdego łańcucha polipeptydowego) lub STOP (które nie kodują żadnego aminokwasu, a przez to oznaczają koniec syntezy danego łańcucha polipeptydowego).
1 nukleotyd | 2 nukleotyd | 3 nukleotyd | |||||||
U | C | A | G | ||||||
U | UUU | (Phe/F) fenyloalanina | UCU | (Ser/S) seryna | UAU | (Tyr/Y) tyrozyna | UGU | (Cys/C) cysteina | U |
UUC | UCC | UAC | UGC | C | |||||
UUA | (Leu/L) leucyna | UCA | UAA | STOP | UGA | STOP | A | ||
UUG | UCG | UAG | STOP | UGG | (Trp/W) tryptofan | G | |||
C | CUU | CCU | (Pro/P) prolina | CAU | (His/H) histydyna | CGU | (Arg/R) arginina | U | |
CUC | CCC | CAC | CGC | C | |||||
CUA | CCA | CAA | (Gln/Q) glutamina | CGA | A | ||||
CUG | CCG | CAG | CGG | G | |||||
A | AUU | (Ile/I) izoleucyna | ACU | (Thr/T) treonina | AAU | (Asn/N) asparagina | AGU | (Ser/S) seryna | U |
AUC | ACC | AAC | AGC | C | |||||
AUA | ACA | AAA | (Lys/K) lizyna | AGA | (Arg/R) arginina | A | |||
AUG | (Met/M) metionina | ACG | AAG | AGG | G | ||||
G | GUU | (Val/V) walina | GCU | (Ala/A) alanina | GAU | (Asp/D) kwas asparaginowy | GGU | (Gly/G) glicyna | U |
GUC | GCC | GAC | GGC | C | |||||
GUA | GCA | GAA | (Glu/E) kwas glutaminowy | GGA | A | ||||
GUG | GCG | GAG | GGG | G | |||||
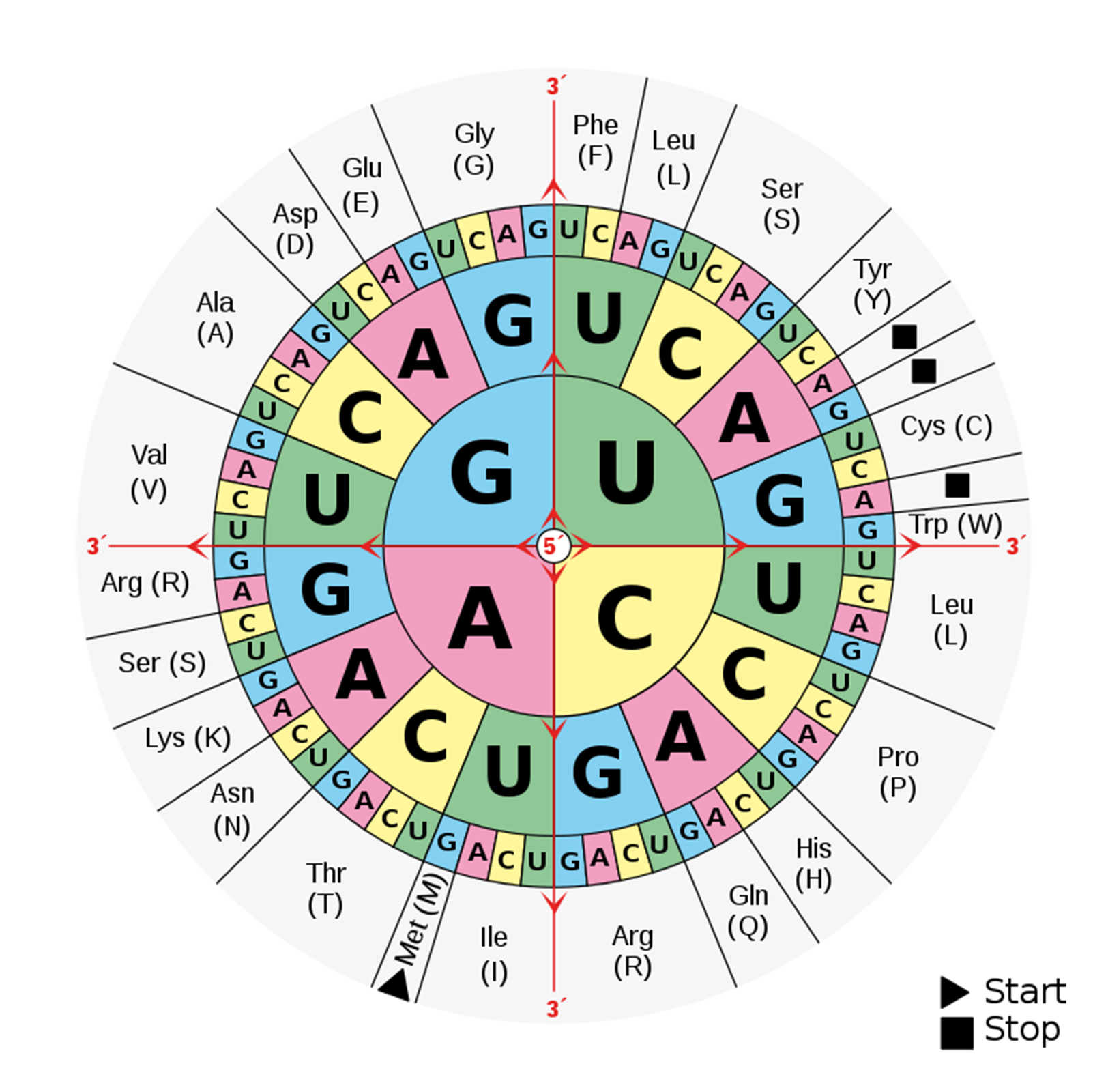
Ilustruje ona wszystkie możliwe kombinacje w kodonie oraz przypisane im aminokwasy. Cała struktura podzielona jest na cztery ćwiartki i zawiera cztery pierścienie współśrodkowe. Trzy pierścienie (zaczynając od środka) zawierają symbole nukleotydów, a czwarty pierścień zawiera symbole aminokwasów.
Kolistą tabelę kodu genetycznego odczytuje się od najbardziej wewnętrznego pierścienia, w którym znajdują się cztery nukleotydy: G, U, A i C. Kolejnym krokiem jest odczytanie drugiego nukleotydu w kodonie, umieszczonego na drugim pierścieniu. Do każdego pierwszego nukleotydu można dopasować jeden z czterech nukleotydów, ułożonych w kolejności: U, C, A, G. Trzeci nukleotyd odczytywany jest z najbardziej zewnętrznego pierścienia koła zawierającego nukleotydy. Do drugiego nukleotydu w kodonie można dopasować także jeden z czterech nukleotydów uszeregowanych w takiej kolejności jak nukleotydy w poprzednim pierścieniu. Aby ułatwić odczytywanie kolejnych nukleotydów kodonu zostały one zapisane czcionką o różnej wielkości: od największej przy nukleotydzie pierwszym do najmniejszej dla ostatniego nukleotydu z kodonu.
Dodatkowym ułatwieniem jest oznakowanie nukleotydów kolorami, co ułatwia szybką lokalizację nukleotydów, zwłaszcza w pozycji trzeciej.
Każdemu z 61 kodonów (trójek nukleotydów) przyporządkowano jeden aminokwas, którego symbol lub nazwę umieszczono na ostatnim, zewnętrznym pierścieniu koła. Trzy kodony to kodony STOP.
Kodon START oznaczony jest jako trójkąt, opatrzony także opisem „Met (M)”, ponieważ koduje aminokwas metioninę. Jest on pierwszym z aminokwasów w tworzonej sekwencji białka. Trzy z kodonów oznaczono za pomocą kwadratów. Są to kodony STOP i nie mają one przypisanych aminokwasów, gdyż stanowią sygnał dla zakończenia syntezy łańcucha polipeptydowego.
Odczytywanie kodonów na mRNA podczas syntezy łańcucha polipeptydowego rozpoczyna się od zlokalizowania kodonu START. Na podstawie kolejnych kodonów są dołączane odpowiednie aminokwasy. Synteza białka trwa do odczytania kodonu STOP. Odczytywanie kodonów w mRNA odbywa się od końca 5′ do końca 3′, które warunkują kolejność aminokwasów w polipeptydzie od N‑końca pierwszego aminokwasu (metioniny) do C‑końca ostatniego. Koniec N polipeptydu stanowi aminokwas z wolną grupą aminową, a koniec C – aminokwas z wolną grupą karboksylową.
Zapoznaj się z audiobookiem „Złamanie kodu genetycznego”, a następnie wykonaj polecenia.
Cechy kodu genetycznego
Kod genetyczny posiada charakterystyczne cechy. Jest: trójkowy, jednoznaczny, zdegenerowany, bezprzecinkowy, uniwersalny oraz kolineralny.
Francis Crick zwrócił uwagę na to, że istnieje pewne odstępstwo od parowania zasad azotowych budujących nukleotydy w momencie przyłączania się do kodonu cząsteczki mRNA antykodonu cząsteczki tRNA podczas translacji. Różnych rodzajów cząsteczek tRNA jest tylko 40, a więc niektóre z nich muszą rozpoznawać więcej niż jeden rodzaj kodonu w cząsteczce mRNA. Według reguły, nazwanej przez F. Cricka regułą tolerancji, zasada azotowa nukleotydu znajdująca się w trzeciej pozycji kodonu może łączyć się z zasadą azotową nukleotydu znajdującego się w trzeciej pozycji antykodonu niezgodnie z regułą komplementarności np. U może łączyć się z A, ale także z G. Dlatego też kodony mRNA kodujące te same aminokwasy różnią się nukleotydem w pozycji trzeciej. Pozycja pierwsza i druga kodonu są takie same.
Sprawdź się w multimedialnej symulacji
Znajdź kodon START, aby przeprowadzić transkrypcję, a następnie, przy użyciu tabeli kodu genetycznego, poznać sekwencję zakodowanego w DNA peptydu.

Zasób interaktywny dostępny pod adresem https://zpe.gov.pl/a/D9HKLZ58J
1 nukleotyd | 2 nukleotyd | 3 nukleotyd | |||||||
U | C | A | G | ||||||
U | UUU | (Phe/F) fenyloalanina | UCU | (Ser/S) seryna | UAU | (Tyr/Y) tyrozyna | UGU | (Cys/C) cysteina | U |
UUC | UCC | UAC | UGC | C | |||||
UUA | (Leu/L) leucyna | UCA | UAA | STOP | UGA | STOP | A | ||
UUG | UCG | UAG | STOP | UGG | (Trp/W) tryptofan | G | |||
C | CUU | CCU | (Pro/P) prolina | CAU | (His/H) histydyna | CGU | (Arg/R) arginina | U | |
CUC | CCC | CAC | CGC | C | |||||
CUA | CCA | CAA | (Gln/Q) glutamina | CGA | A | ||||
CUG | CCG | CAG | CGG | G | |||||
A | AUU | (Ile/I) izoleucyna | ACU | (Thr/T) treonina | AAU | (Asn/N) asparagina | AGU | (Ser/S) seryna | U |
AUC | ACC | AAC | AGC | C | |||||
AUA | ACA | AAA | (Lys/K) lizyna | AGA | (Arg/R) arginina | A | |||
AUG | (Met/M) metionina | ACG | AAG | AGG | G | ||||
G | GUU | (Val/V) walina | GCU | (Ala/A) alanina | GAU | (Asp/D) kwas asparaginowy | GGU | (Gly/G) glicyna | U |
GUC | GCC | GAC | GGC | C | |||||
GUA | GCA | GAA | (Glu/E) kwas glutaminowy | GGA | A | ||||
GUG | GCG | GAG | GGG | G | |||||
AUG UAC CAA CAC GGC AAG UGA
Przebieg transkrypcji
Transkrypcja jest pierwszym etapem ekspresji genu. Polega na zsyntetyzowaniu cząsteczki RNA (np. mRNA, tRNA, rRNA) na podstawie informacji genetycznej zawartej w DNA. Proces ten zachodzi w jądrze komórkowym (u eukariontów) lub w cytoplazmie (u prokariontów) zgodnie z zasadą komplementarności.
Podwójna helisa DNA składa się z dwóch nici komplementarnych względem siebie: nici kodującej i nici matrycowej. Nić matrycowa to nić transkrybowana. Nić kodująca nie ulega transkrypcji – jej sekwencja, podobnie jak sekwencja powstającego RNA, jest komplementarna do nici matrycowej, z tą różnicą, że w RNA zamiast nukleotydów zawierających tyminę występują nukleotydy z uracylem.
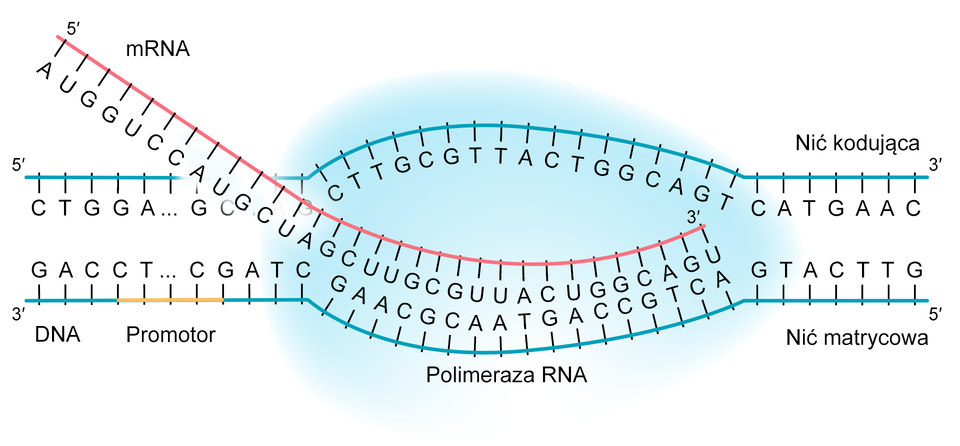
Transkrypcji podlega odcinek DNA zawarty między promotorem a terminatorem lub sekwencją terminalną. Reakcję katalizuje enzym polimeraza RNA zależna od DNA, a substratami do budowy RNA są trójfosforany rybonukleozydów (ATP, GTP, CTP i UTP).
Człowiek i inne organizmy eukariotyczne mają trzy rodzaje polimerazy RNA: I, II i III. Każdy specjalizuje się w transkrypcji określonych klas genów:
Polimeraza RNA I odpowiada za syntezę pre‑rRNA, z którego powstaje rRNA, wchodzący w skład rybosomów. Polimeraza RNA I działa jedynie w obrębie jąderka.
Polimeraza RNA II odpowiada za transkrypcję pozostałych genów. Wskutek jej działalności powstaje pre‑mRNA. Syntetyzuje ona również enzymatyczny snRNA, który jest wykorzystywany w dalszej obróbce pre‑mRNA.
Polimeraza RNA III odpowiada za syntezę tRNA.
Rośliny mają dodatkowe dwa rodzaje polimerazy RNA: IV i V, które biorą udział w syntezie małych RNA.
Przebieg transkrypcji u prokariontów i eukariontów jest odmienny, jednak w obu przypadkach proces ten składa się z trzech etapów: inicjacji, elongacji i terminacji.
Transkrypcja u prokariontów
Geny bakterii to geny ciągłegeny ciągłe, co oznacza, że zsyntetyzowany mRNA od razu może służyć jako matryca do tworzenia białka. U prokariontów, kilka genów może mieć wspólny promotor (np. geny kodujące enzymy jednego szlaku metabolicznego), a przez to wspólnie podlegać transkrypcji. Powstający wówczas mRNA określany jest policistronowym, ponieważ jest matrycą do syntezy kilku białek, należących najczęściej do jednego szlaku metabolicznego.
Zespół genów u organizmów prokariotycznych, które leżą obok siebie, są kontrolowane przez ten sam promotor i są jednocześnie przepisywane na jedną cząsteczkę RNA nazywany jest operonem.
Ponieważ bakterie nie posiadają jądra komórkowego, a ich materiał genetyczny znajduje się bezpośrednio w cytoplazmie, powstające mRNA od razu wiąże się z rybosomami, gdzie na jego podstawie syntezowane są białka. Translacja u prokariontów rozpoczyna się zatem jeszcze przed zakończeniem transkrypcji.
Transkrypcja u eukariontów
W komórkach eukariotycznych proces transkrypcji jest wieloetapowy i znacznie bardziej złożony niż u prokariontów. Najważniejsze różnice dotyczą:
oddzielenia transkrypcji od translacji barierą jądrową, przez co oba procesy nie zachodzą jednocześnie,
udziału czynników transkrypcyjnych w inicjacji procesu,
modyfikacji pierwotnego transkryptu.
Proces inicjacji transkrypcji wymaga obecności specjalnych białek – tzw. czynników transkrypcyjnych.czynników transkrypcyjnych. To one lokalizują promotor i leżący za nim początek genu. Polimeraza przyłącza się dopiero po związaniu odpowiednich czynników transkrypcyjnych do DNA.
Geny eukariontów są w większości genami nieciągłymi. Oznacza to, że sekwencje kodujące fragmenty białek – eksony – są poprzedzielane fragmentami niekodującymi – intronami. W procesie transkrypcji przepisywane są zarówno fragmenty kodujące jak i niekodujące, w wyniku czego powstaje pierwotny transkrypt - prekursorowy mRNA, (pre‑mRNApre‑mRNA).
Przed opuszczeniem jądra komórkowego pre‑mRNA podlega modyfikacjom potranksrypcyjnym, w wyniku czego powstaje mRNA. Modyfikacje potranskrypcyjne, nazywane również dojrzewaniem mRNA obejmują:
modyfikacje końców pre‑mRNA
składanie mRNA (ang. splicing)
Modyfikacje końców pre‑mRNA polegają na dołączeniu do końca 5’ tzw. czapeczki (ang. cap), będącej zmodyfikowanym nukleozydemnukleozydem guanozyny, oraz na poliadenylacji końca 3’, czyli dołączeniu ogona poli(A) złożonego z licznych nukleotydów adenylowych. Obie te struktury stabilizują cząsteczkę, chroniąc ją przed rozkładem enzymatycznym w cytozolu.
Składanie RNA polega na przecięciu pre‑mRNA na granicy poszczególnych eksonów i intronów, a następnie złożeniu nici mRNA bez intronów. Splicing może zachodzić dwoma sposobami:
z udziałem spliceosomuspliceosomu, który rozpoznaje granice intronów i egzonów,
samodzielnie, gdy intron działa jak rybozym i katalizuje własne wycięcie.
Zapoznaj się z audiobookiem „Modyfikacje potranskrypcyjne RNA u Eukaryota”, a następnie wykonaj polecenia.
Odwrotna transkrypcja jako etap cyklu infekcyjnego retrowirusów
U retrowirusów (do których należy m.in. ludzki wirus niedoboru odporności – HIV, ang. human immunodeficiency virus), których genom stanowi RNA, występuje odwrotna transkrypcja. Polega ona na wytworzeniu jednoniciowego DNA (ssDNA – ang. single‑stranded DNA) z wirusowego RNA. Proces ten przeprowadza specjalny enzym − odwrotna transkryptaza. Dzięki temu powstaje hybryda DNA–RNA. Następnie rybonukleaza uwalnia nowo powstały jednoniciowy DNA, a polimeraza DNA syntetyzuje na ssDNA drugą, komplementarną nić. Powstaje dwuniciowy DNA (dsDNA – double‑stranded DNA), który zostaje wprowadzony do jądra zainfekowanej komórki i – przy udziale enzymu integrazy – wbudowany do jądrowego DNA.
Translacja - biosynteza białka na rybosomach
Translacja jest drugim etapem odczytywania informacji genetycznej, podczas którego – na podstawie informacji zapisanej w nici mRNA – syntetyzowany jest polipeptyd.
Proces translacji zachodzi na rybosomach, które zlokalizowane są w cytoplazmie lub na błonach siateczki śródplazmatycznej szorstkiej. Do prawidłowego przebiegu translacji oprócz rybosomów niezbędne są:
mRNA – matrycowe RNA, na podstawie którego odczytywana jest informacja o sekwencji aminokwasów w łańcuchu polipeptydowym;
aminokwasy białkowe – 20 różnych aminokwasów wchodzących w skład białek;
tRNA – transportujący/transferowy RNA, czyli cząsteczki RNA, które mają za zadanie wiązanie wolnych aminokwasów w cytoplazmie i ich transport do rybosomów;
czynniki inicjacji, elongacji i terminacji translacji – białka lub kompleksy białkowe odpowiedzialne za procesy translacji na każdym z jej etapów;
GTPGTP – źródło energii, m.in. do przesuwania się rybosomu po mRNA.
Rola tRNA w procesie translacji
tRNA pełni w translacji dwie główne funkcje:
rozpoznaje właściwy aminokwas na podstawie informacji zapisanej w kodzie genetycznym zawartym w mRNA, podczas interakcji tRNA oraz mRNA;
przenosi właściwy aminokwas do tworzonego na rybosomie łańcucha polipeptydowego.
Funkcje tRNA są ściśle związane z jego budową, w szczególności z występowaniem pętli antykodonowej i ramienia akceptorowego. Ramię akceptorowe zakończone jest wolnym końcem 3’, do którego przyłączany jest aminokwas, który tRNA transportuje do rybosomu.

W trakcie biosyntezy białka wykorzystywane są różne rodzaje tRNA, ponieważ każdy z nich przenosi wyłącznie jeden, swoisty aminokwas. Proces przyłączania aminokwasu do tRNA określa się mianem aminoacylacji, natomiast tRNA połączony z aminokwasem nazywany jest aminoacylo‑tRNA (aa‑tRNA). Energia do reakcji aminoacylacji pochodzi z hydrolizy ATP, a enzymem przeprowadzającym ten proces - syntaza aminoacytlo‑tRNA.
Pętla antykodonowa tRNA zawiera trzy nukleotydy - tzw. antykodon, który jest komplementarny do kodonu w mRNA. Dzięki właściwemu dopasowaniu nukleotydów antykodonu i kodonu, do rybosomu przetransportowany zostaje odpowiedni aminoacylo‑tRNA.
Przebieg translacji
W przebiegu translacji wyróżnia się trzy etapy: inicjacji, elongacji oraz terminacji. Do zajścia każdego z tych etapów potrzebna jest energia, której źródłem jest hydroliza GTP.
Inicjacja translacji
Inicjacja translacji polega na:
rozpoznaniu przez odpowiednie tRNA kodonu START na nici mRNA
utworzeniu rybosomu składającego się z dwóch podjednostek: mniejszej i większej.
Proces inicjacji translacji u eukariontów rozpoczyna się od utworzenia kompleksu złożonego z mniejszej podjednostki rybosomu oraz inicjatorowego tRNA, który transportuje metioninę. Cząsteczka metionylo‑tRNA zajmuje specyficzne miejsce w rybosomie, zwane miejscem P. Tak przygotowany kompleks przyłącza się do końca 5' cząsteczki mRNA i przesuwa wzdłuż nici w poszukiwaniu sygnału do rozpoczęcia syntezy białka. Sygnałem tym jest kodon START (AUG). Gdy antykodon tRNA rozpozna go na zasadzie komplementarności, ruch podjednostki mniejszej zostaje zahamowany, po czym przyłącza się do niej podjednostka większa tworząc rybosom.
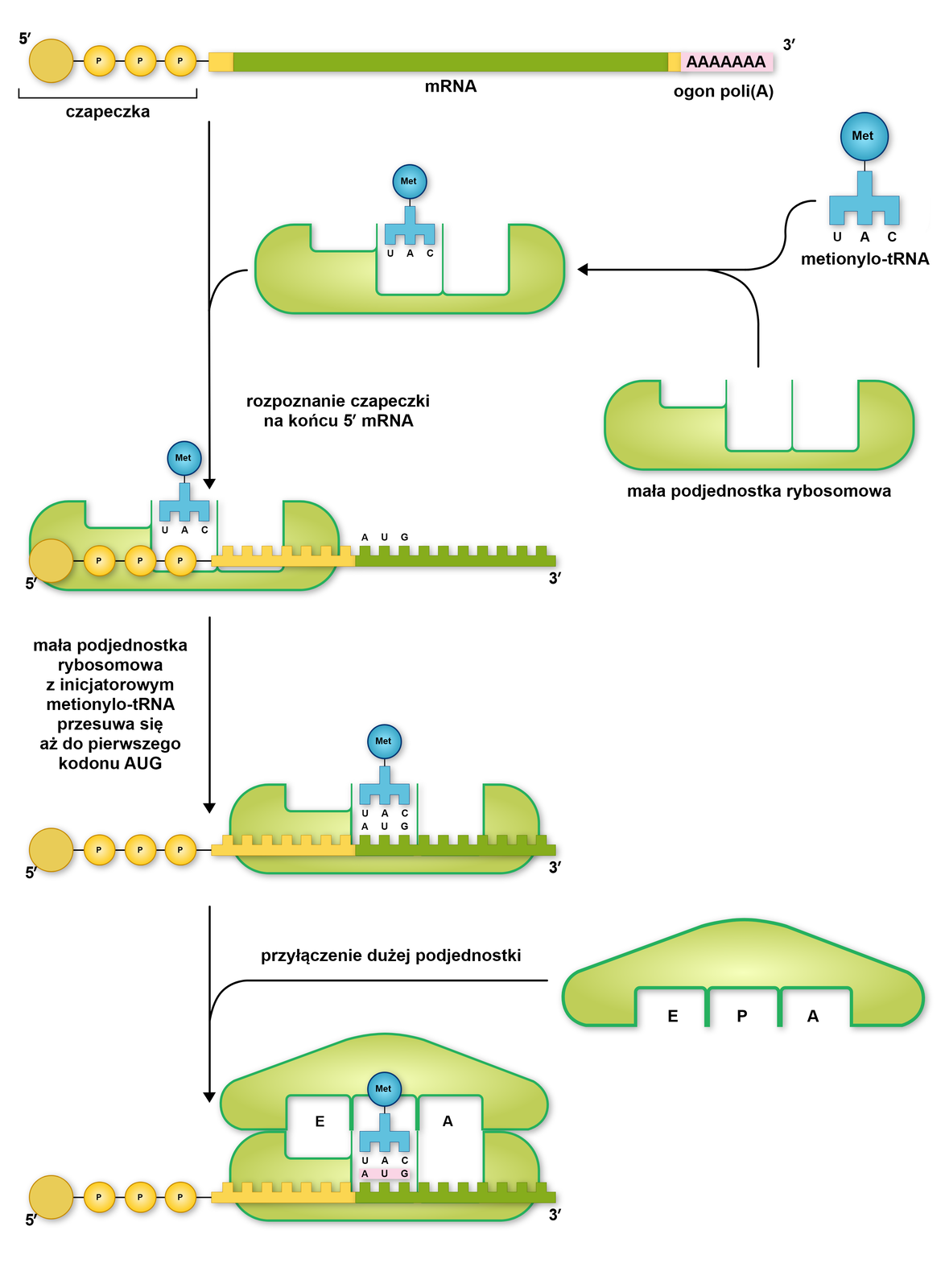
Z jedną cząsteczką mRNA łączy się zwykle więcej niż jeden rybosom. Taki zespół rybosomów syntetyzujących równocześnie białko na jednej matrycy mRNA określany jest jako polisom (polirybosom).
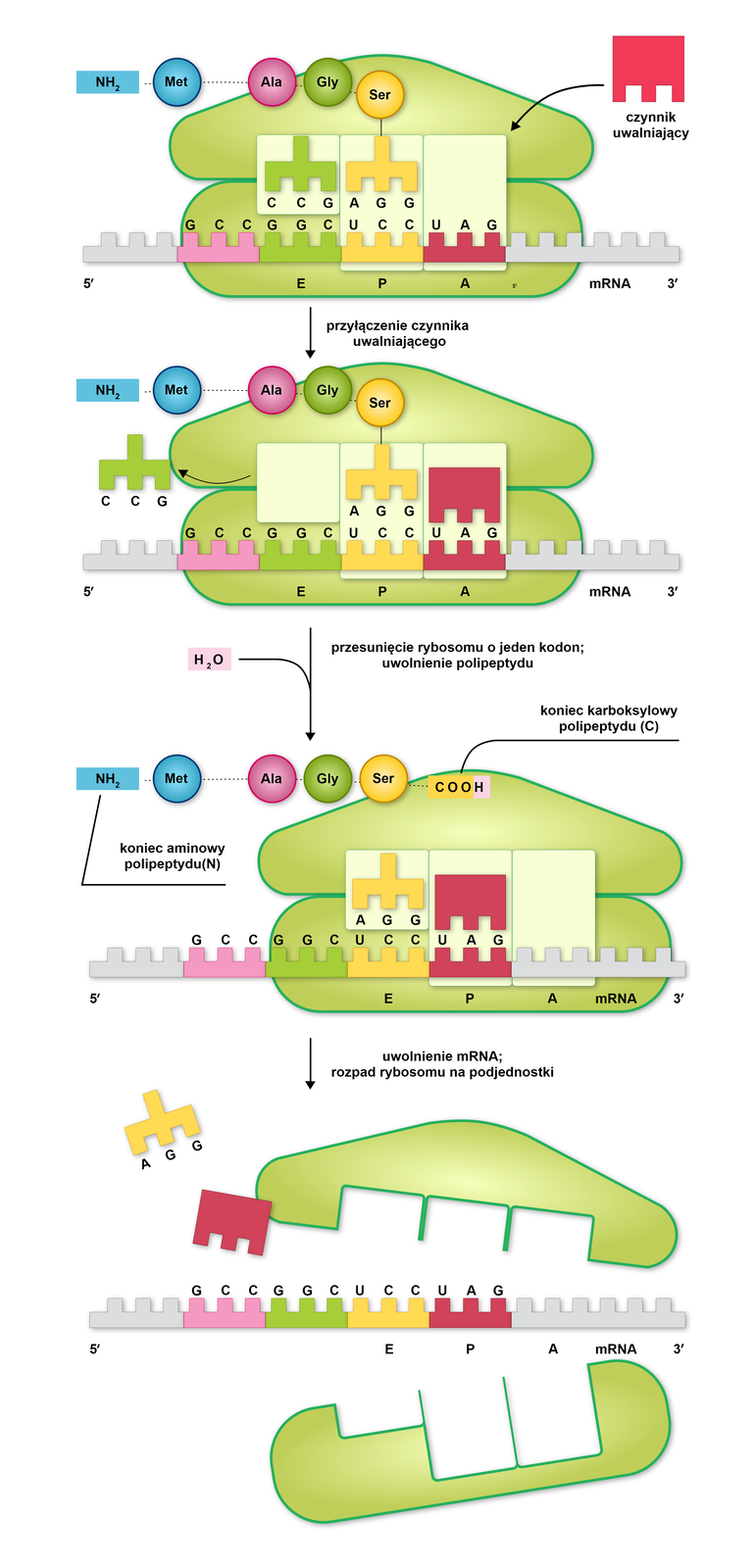
Elongacja
Elongacja polega na wydłużaniu łańcucha peptydowego i rozpoczyna się od przyłączenia w miejscu A rybosomu następnej cząsteczki aminoacylo‑tRNA, której antykodon odpowiada kolejnemu kodonowi w mRNA. Między metioniną a nowym aminokwasem tworzy się wówczas, przy udziale rRNA dużej jednostki rybosomu, wiązanie peptydowe, metionina odłącza się od tRNA, a rybosom przesuwa o trzy nukleotydy (o kodon). tRNA związany przynajmniej z dwoma aminokwasami nosi nazwę peptydylo‑tRNA.
W miejscu P znajduje się teraz nowo przyłączony peptydylo‑tRNA (z którym związany jest łańcuch dwóch aminokwasów). Cząsteczka tRNA, która jako pierwsza przyłączyła się do mRNA, zostaje przesunięta do miejsca E, z którego opuszcza rybosom. Do zwolnionego miejsca A przyłącza się natomiast kolejna cząsteczka aminoacylo‑tRNA i cały proces przebiega według poprzedniego schematu aż do końca translacji.

Terminacja translacji
Terminacja translacji rozpoczyna się w momencie rozpoznania w sekwencji mRNA kodonu STOP (UAA, UAG, UGA). Kiedy miejsce A natrafi na kodon STOP (UAA, UAG lub UGA). Wówczas zamiast aminoacylo‑tRNA przyłącza się do niego białko zwane czynnikiem uwalniającym. Powoduje ono hydrolizę wiązania między powstałym polipeptydem a miejscem P rybosomu - polipeptyd odłącza się, a kompleks translacyjny rozpada.
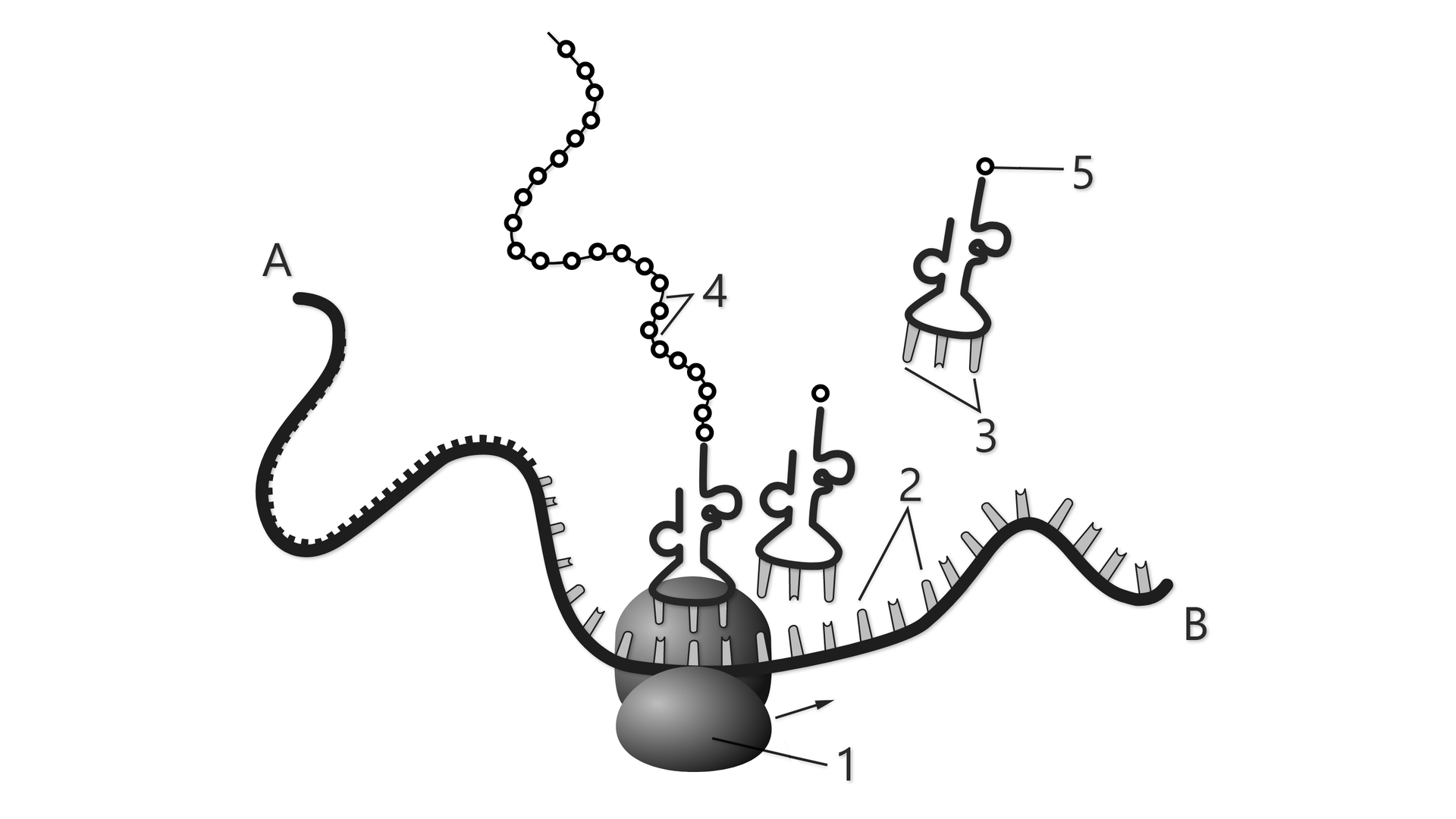
Modyfikacje potranslacyjne bialek
Białka wytworzone w procesie translacji, aby mogły pełnić swoje funkcje w komórce, wymagają dodatkowych zmian w budowie. Zmiany te zachodzą w cytozolu lub organellach, takich jak siateczka śródplazmatyczna i aparat Golgiego i określane są mianem modyfikacji potranslacyjnych. Obejmują one m.in.:
obróbkę proteolityczną,
dodawanie grup chemicznych.
Obróbka proteolityczna
Obróbka proteolityczna polega na usuwaniu z łańcucha peptydowego pojedynczych aminokwasów lub dłuższych fragmentów.
Przykładem obróbki proteolitycznej jest usunięcie metioniny z N‑końca polipeptydu. Każde białko powstające w komórce posiada ten aminokwas na N‑końcu, co wynika z funkcji „START” kodującego metioninę kodonu AUG w procesie translacji. Większość białek nie potrzebuje jednak tego aminokwasu na końcu łańcucha, dlatego jest on usuwany przez odpowiednie enzymy -proteazy. Powstałe w komórce białko zostaje zdegradowane średnio po 8 godz. Do jednych z najszybciej degradowanych białek należy dekarboksylaza ornityny, której czas półtrwania to jedynie 11 min. Dłuższy czas półtrwania mają z kolei białka strukturalne, takie jak miozyna i aktyna (około miesiąca).

Inny rodzajem obróbki proteolitycznej jest częściowa proteoliza, która polega na usunięciu fragmentu polipeptydu, co ułatwia białku przyjęcie odpowiedniej struktury przestrzennej (konformacji). Modyfikacji takiej podlega m.in. insulina: ze środka polipeptydu usuwanych jest 31 aminokwasów. Częściowa proteoliza jest charakterystyczną modyfikacją dla wielu hormonów i proteaz.

Dodawanie grup chemicznych
Spośród modyfikacji polegających na dodawaniu grup chemicznych najczęściej spotyka się przyłączanie grupy fosforanowej (fosforylacjafosforylacja), grupy tiolowej (tiolacjatiolacja) oraz reszty cukrowej (glikozylacjaglikozylacja).
Zapoznaj się z symulacją „Modyfikacja potranslacyjna”, a następnie wykonaj polecenia.

Zasób interaktywny dostępny pod adresem https://zpe.gov.pl/a/D9HKLZ58J
Symulacja dotyczy modyfikacji potranslacyjnych białka. Czym są modyfikacje potranslacyjne? To zmiany w budowie białka nastepujące po jego translacji. Wpływają one na jego właściwości chemiczne i fizyczne, stabilność i aktywność, a zatem na jego funkcjonowanie. Struktura pierwszorzędowa warunkuje budowę białka, ale nie zawsze umożliwia jego aktywację. Fosforylacja białka. To proces, który polega przyłączeniu reszty fosforanowej do białka. Odbywa się to dzięki enzymom zwanym kinazami, które zużywają energię zgromadzoną w ATP. Fosforylacja białek umożliwia ich aktywację. Na ilustracji jest długi łańcuch zbudowany z szarych, niebieskich, pomarańczowych i żółtych odcinków. Część łańcucha białka zbudowana z żółtych odcinków połączonych z pomarańczowymi odcinkami to odcinek odpowiadający wzorowi: atom fosforu P łączy się z czterech stron z atomami tlenu - u góry wiązaniem podwójnym, a na dole oraz po lewej i prawej stronie z anionami tlenu. Tiolacja białka. To odwracalna, kowalencyjna modyfikacja białek polegająca na utworzeniu mostków disiarczkowych między grupami tiolowymi białek. Modyfikacja ta chroni grupy -SH przed nieodwracalnym utlenianiem i nieodwracalną utratą biologicznej aktywności. Na ilustracji jest łańcuch białka zbudowany z odcinków w kolorach szarym, niebieskim, czerwonym, żółtym. W jednym miejscu pokazano, jak stykają się ze sobą żółte odcinki. To mostek disiarczkowy. Pojawia się zapis: HS, obok którego jest zapis SH, poprowadzono od tych grup linie w dół do linii poziomej, strzałki w dwie strony, obok symbolu S jest linia pozioma do symbolu S - od nich linie w dół do linii poziomej. Glikozylacja białka. Polega na przyłączeniu reszty cukrowej do białka poprzez wiązanie N‑glikozydowe lub wiązanie O‑glikozydowe. N‑glikozylacja polega na przyłączeniu reszty cukru do atomu azotu łańcucha bocznego jednej z reszt aminokwasowych białka, a O‑glikozylacja na przyłączeniu reszty cukru do atomu tlenu łańcucha bocznego jednej z reszt aminokwasowych białka. Na ilustracji jest łańcuch białka zbudowany z odcinków szarych, niebieskich, czerwonych. W jednym miejscu do niebieskiego odcinka przyłącza się wzór chemiczny: od lewej strony jest grupa HO, łączy się wiązaniem pojedynczym z atomem węgla, ten łączy się z kolejnym atomem węgla. Ten u góry wiązaniem w kształcie klina łączy się z grupą OH, a w prawo z atomem węgla połączonym wiązaniem podwójnym z atomem tlenu. Wzór ten zamienia się w kolejny wzór, jest on pionowy: grupa CH łączy się po lewej stronie z grupą hydroksylową, na dole z grupą metylową, która łączy się atomem tlenu, natomiast na górze łączy się z grupą CH połączoną wiązaniem podwójnym z atomem tlenu.
Fosforylacja i tiolacja warunkują odpowiednią strukturę przestrzenną białka, co ma kluczowe znaczenie dla jego aktywności biologicznej. Np. fosforylacja i tiolacja białek enzymatycznych mogą powodować odsłonięcie lub zamaskowanie ich centrum aktywnego. Z kolei glikozylacja umożliwia specyficzne oznakowanie białek, co ułatwia ich segregację i prawidłową lokalizację w komórce.
Prawidłowe funkcjonowanie komórek zależy w dużej mierze od aktywności tworzących je białek. W związku z tym powstające białka są po pewnym czasie degradowane. Dzięki temu możliwe jest usuwanie białek źle sfałdowanych, a także niepotrzebnych już enzymów
Sygnałem do rozpoczęcia degradacji białka jest poliubikwitynacja, czyli przyłączenie przez ligazę ubikwitynową polimerów ubikwityny do polipeptydu. Białka znakowane ubikwityną rozkładane są przez proteasom.
Średni czas życia przeciętnego białka w komórce wynosi ok. 8 godz. Do jednych z najszybciej degradowanych białek należy enzym - dekarboksylaza ornityny, której czas półtrwania to jedynie 11 min. Dłuższy czas półtrwania mają z kolei białka strukturalne, takie jak miozyna i aktyna (około miesiąca).
Podsumowanie
Ekspresja informacji genetycznej – najważniejsze informacje
Ekspresja genów to proces odczytywania informacji zapisanej w DNA i wytwarzania na jej podstawie białek (łańcuchów polipeptydowych).
Obejmuje dwa główne etapy: transkrypcję (synteza RNA) i translację (synteza białka).
Kod genetyczny
Jest sposobem zapisu informacji genetycznej i określa kolejność aminokwasów w łańcuchu polipeptydowym (białku).
Informacja genetyczna zapisana jest w postaci kodonów (trójek nukleotydów w mRNA).
Cechy kodu: trójkowy, jednoznaczny, zdegenerowany, bezprzecinkowy, uniwersalny, kolineralny.
Transkrypcja
Jest pierwszym etapem ekspresji informacji genetycznej.
Zachodzi w jądrze komórkowym (u eukariontów) lub cytoplazmie (u prokariontów) i obejmuje etapy: inicjacji, elongacji, terminacji.
Produktem transkrypcji u prokariontów jest policistronowy mRNA.
U eukariontów: geny są nieciągłe (eksony + introny), rezultatem transkrypcji jest pierwotny transkrypt, czyli pre‑mRNA, który podlega modyfikacjom potranskrypcyjnym (dojrzewaniu). Obejmują one: ochronę końców pre‑mRNA przez dodanie czapeczki oraz ogona poli(A) oraz składanie mRNA (splicing).
Odwrotna transkrypcja
Występuje u retrowirusów (np. HIV), przeprowadza ją enzym od odwrotna transkryptaza; polega na przepisaniu RNA wirusa na jednoniciowy DNA, który wbudowuje się do genomu gospodarza.
Translacja
Jest drugim etapem ekspresji informacji genetycznej, podczas którego na podstawie kodu genetycznego syntetyzowane są białka (łańcuchy polinukleotydowe).
Zachodzi na rybosomach w cytoplazmie lub na siateczce śródplazmatycznej szorstkiej (u eukariontów) i obejmuje etapy: inicjację, elongację (tworzenia wiązań peptydowych) oraz terminację.
Aminokwasy do rybosomu transportuje tRNA, który zawiera ramię akceptorowe (wiąże aminokwas) oraz pętlę antykodonową (rozpoznaje kodon mRNA).
Proces wiązania aminokwasu do tRNA nazywa się aminola
Etapy translacji: inicjacja (rozpoznanie kodonu AUG - START na mRNA), elongacja (tworzenie wiązań peptydowych), terminacja (rozpoznanie kodonu STOP na mRNA – UAA, UAG, UGA).
Modyfikacje potranslacyjne białek
Białka wytworzone na rybosomach wymagają modyfikacji, aby mogły pełnić swoje funkcje. Do najważniejszych należą: obróbka proteolityczna oraz dodawanie grup chemicznych, które prowadzą do uzyskania przez białko odpowiedniej struktury przestrzennej warunkującej jego funkcje.
Obróbka proteolityczna – usuwanie pojedynczych aminokwasów lub dłuższych fragmentów z łańcucha polipeptydowego (np. metioniny z N‑końca, częściowa proteoliza w insulinie).
Dodawanie grup chemicznych – fosforylacja (reszta fosforanowa), tiolacja (grupa tiolowa), glikozylacja (reszta cukrowa).
Ćwiczenia utrwalające
Sekwencja nukleotydowa: G C U A C G G A G C U A G C U A G C U A G
Sekwencja aminokwasowa: Możliwe odpowiedzi: 1. Alanina - Treonina - Kwas glutaminowy - Leucyna - Alanina - Seryna - STOP, 2. Metionina - Treonina - Seryna - Leucyna - Alanina - Seryna - STOP, 3. Metionina - Treonina - Kwas glutaminowy - Leucyna - Alanina - Seryna - STOP, 4. Alanina - Treonina - Metionina - Leucyna - Alanina - Seryna - STOP
3′ TAC TCA GAT TGT CAT AAC 5′
3 prim TAC TCA GAT TGT CAT AAC 5 prim
Wróć do polecenia na stronie „Na dobry początek” i dopisz brakujące definicje. Pamiętaj, żeby nie kopiować słownika, ale wyjaśnić każde słowo kluczowe w miarę możliwości swoimi słowami.