Przeczytaj
Wskaźniki
WskaźnikiWskaźniki to specjalne zmienne używane do przechowywania adresów, a nie zwykłych wartości. To bardzo użyteczna funkcja języków programowania, która znajduje wiele zastosowań. Prawie wszystkie struktury danych (listy z dowiązaniami, stosy, kolejki, drzewa, tabele haszujące, wykresy) są implementowane za pomocą tych zmiennych.
Przeanalizujmy rysunek:
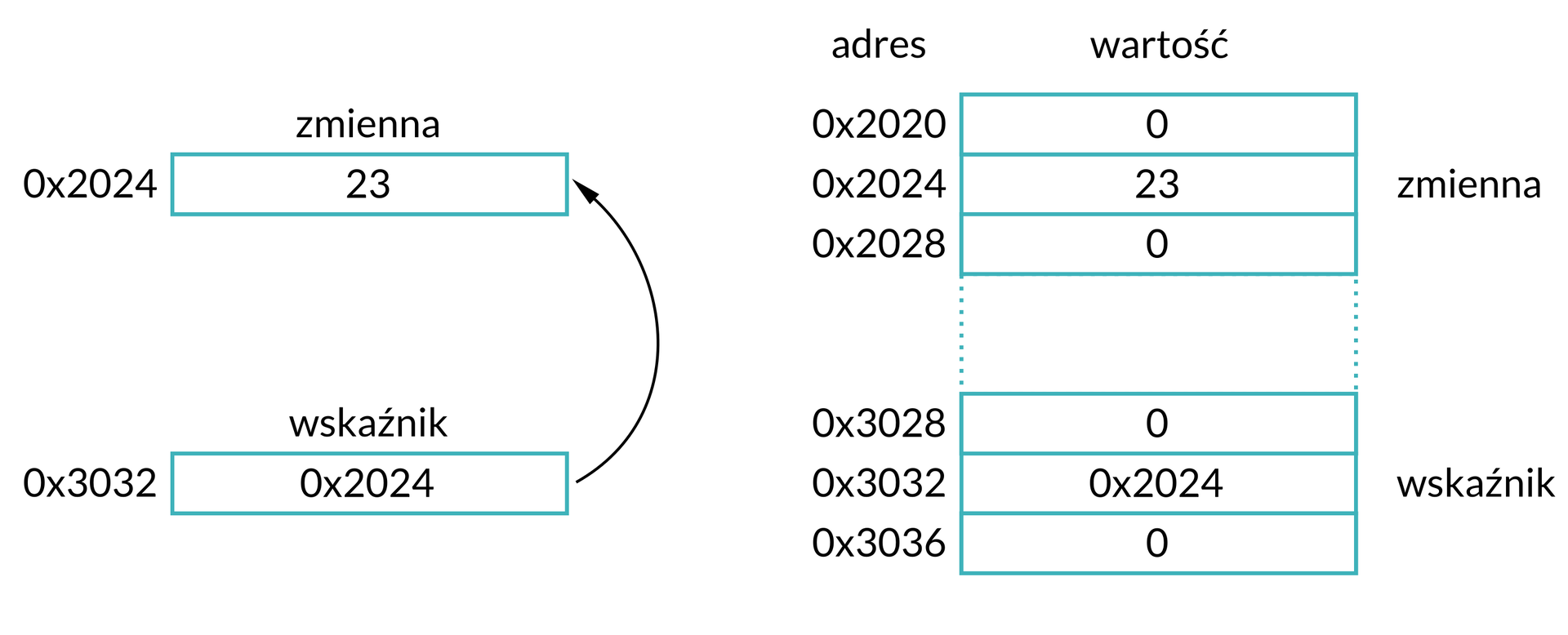
Przedstawiono tu fragment pewnej przykładowej komórki pamięci. Pod adresem 0x2024 przechowywana jest zmienna o wartości 23. Tworząc wskaźnik wskazujący na tę zmienną, uwzględniamy adres (0x2024) jako jego wartość. On również musi być przechowywany w pamięci – w analizowanym przykładzie ulokowany jest pod adresem 0x3032.
Stosowanie wskaźników zapewnia efektywniejsze wykorzystanie miejsca w pamięci. Docelowo przekłada się również na ograniczenie czasu niezbędnego do wykonania wielu operacji zawartych w programach, a tym samym na lepszą wydajność.
Załóżmy, że utworzyliśmy obiekt dużych rozmiarów. Przy przekazywaniu go do funkcji możemy wybrać jedno z dwóch rozwiązań:
przekazanie obiektu bezpośrednio,
przekazanie adresu do obiektu.
Pierwsze rozwiązanie sprawi, że kompilator utworzy kopię tego obiektu w pamięci. Jeśli jednak zdecydujemy się na drugą możliwość, wówczas przetwarzanie zostanie wykonane bezpośrednio na oryginalnym obiekcie, a więc zaoszczędzimy czas oraz zasoby pamięci wymagane podczas powielania oryginalnego obiektu.
Oto zalety stosowania wskaźników:
Mogą zmniejszyć długość naszego programu, a zarazem ułatwić procesy związane z analizą kodu, np. odszukiwanie błędów.
Są wydajne w obsłudze tabel danych.
Zastosowanie tablicy wskaźników składającej się z ciągów znaków skutkuje oszczędnością miejsca na dane w pamięci.
Wskaźnik umożliwia nam dostęp do zmiennej zdefiniowanej poza funkcją.
Stos i sterta
Gdy mowa o dynamicznej alokacji pamięci, warto zagłębić się w mechanizmy, za pomocą których programy radzą sobie z przechowywaniem zmiennych, obiektów i wszelkiego typu danych w pamięci komputera. Niezależnie od języka programowania należy wyróżnić dwa kluczowe rodzaje pamięci: stos oraz stertę.
Stos to określone miejsce w pamięci przechowujące m.in. tymczasowe zmienne, czyli zmienne lokalne dla danej funkcji (niezbędne do jej działania), ale również np. wybrane rejestry procesora. Wartościami umieszczonymi w stosie zarządza automatycznie program. Najistotniejszą cechą stosu jest jego sprecyzowana struktura. Przenoszone do niego dane są po kolei lokowane jedne na drugich – wartości, które zostaną umieszczone w stosie jako pierwsze, będą stanowiły jego podstawę, natomiast ostatnie dołożone dane można uznać za wierzchołek. Opisana konstrukcja stosu wymusza również określony sposób odczytywania wartości w nim zawartych. Pobieranie danych musimy rozpocząć od elementu znajdującego się na samej górze (czyli wierzchołka) i kontynuować po kolei aż do ostatniego elementu (czyli podstawy). Oznacza to, że dane odczytywane są ze stosu w kolejności odwrotnej do kolejności ich zapisywania. Taki sposób operowania na pamięci charakteryzowany jest jako stos zwany LIFOLIFO. Należy do dynamicznych struktur danych, o których więcej informacji znajdziesz w e‑materiale Dynamiczne struktury danychDynamiczne struktury danych.
Sterta to rodzaj pamięci, który pozwala na bardziej elastyczny niż w przypadku stosu tryb alokacji. Elementy ulokowane w stercie są przechowywane nie w sposób liniowy, lecz hierarchiczny – przypominający strukturę drzewa. Sterta nie zawsze jest zarządzana automatycznie i to programista odpowiedzialny jest za manipulowanie ulokowaną w niej pamięcią. Zarządzanie stertą jest więc bardziej złożone i bardziej wymagające dla programisty. Do tego istnieje tu ryzyko wpływu błędów ludzkich na przebieg całego procesu.
To, czy dane zmienne będą przechowywane w stosie, czy w stercie, zależy od wybranego języka programowania. Np. w przypadku języka Java utworzone obiekty lokowane są w stercie, podczas gdy w stosie znajdziemy zmienne referencyjnezmienne referencyjne (adresy do obiektów), typy prymitywnetypy prymitywne (np. zmienne typu int, float itd.) oraz informacje o wykonaniu metody (np. lokalne zmienne metody, informacje o kolejności wywołania metody).
W zależności od języka programowania, w stercie znajdziemy również obiekty zadeklarowane dynamicznie w trakcie działania programu. Do obiektów znajdujących się w stercie odwołujemy się przy użyciu referencji i wskaźników przechowywanych w stosie.
To, jak program obsługuje stos oraz stertę, zależy od języka programowania. Przeanalizujmy różnice pomiędzy tymi dwoma typami pamięci:
Stos | Sterta |
|---|---|
liniowa struktura danych | skomplikowana, hierarchiczna struktura danych |
szybkie tworzenie zmiennych | powolny proces ze względu na skomplikowaną strukturę |
ograniczony rozmiar pamięci | nieograniczona pamięć (jeśli nie jest nadużywana) |
szybki dostęp | dosyć wolny dostęp |
automatycznie zarządzany przez system operacyjny fragment pamięci | możliwość zwolnienia zarezerwowanych bloków pamięci przez programistę lub przez mechanizmy wirtualnego środowiska uruchomieniowego |
szybkie operacje ze względu na prostotę struktury | powolna dealokacja pamięci ze względu na konieczność odnalezienia komórek o określonym adresie |
brak możliwości zmiany rozmiaru zmiennych | możliwość dynamicznej alokacji przez obiekty potrzebnego bloku w pamięci w trakcie działania programu |
zwiększone ryzyko przepełnienia stosu przez tworzenie w nim zbyt wielu obiektów lub głębokie rekurencje | wyjątkowo rzadkie przypadki przepełnienia pamięci |
Rodzaje tablic
Tablice w programowaniu nazywane są liniowymi typami danych. Tablicę definiuje się jako skończony uporządkowany zbiór jednorodnych danych, przechowywanych w ciągłych lokalizacjach pamięci.
Struktury te umożliwiają bezpośredni dostęp do dowolnego elementu po indeksie w stałym czasie , niezależnie od rozmiaru tablicy. Czas na pobranie pierwszego elementu jest taki sam, jak czas na pobranie setnego czy tysięcznego elementu.
Tablice statyczne
Dotychczas pracowaliśmy tylko na jednym rodzaju tablic – na tablicach statycznych, czyli takich, których rozmiar jest znany już w momencie kompilacji programu. Tablice te mają stały rozmiar i przechowywane są w miejscu pamięci zwanym stosem.
Jeśli zaistnieje potrzeba wczytania pewnej liczby danych o nieznanym rozmiarze, tablice statyczne mogą okazać się nieodpowiednie. Rozmiar stosu w pamięci jest ograniczony, co sprawia, że znacznie ograniczony jest również rozmiar tablicy statycznej. Jeśli rozmiar przechowywanych danych w końcu przekroczy pojemność pamięci dostępnej dla stosu, przepełni się on, co może się ujawniać przez błąd przepełnienia stosu (ang. stack overflow).
Tablice dynamiczne
W przeciwieństwie do tablic statycznych, tablice dynamicznetablice dynamiczne charakteryzują się tym, że ich rozmiar nie jest znany w momencie kompilacji – określany jest on dopiero w trakcie działania programu. W ten sposób możemy np. umożliwić użytkownikowi jego zdefiniowanie lub modyfikację w zależności od potrzeb. Gdy więc zachodzi konieczność przechowania danych niewiadomego rozmiaru, tablice dynamiczne będą znacznie lepszym wyborem niż ich statyczna alternatywa.
Do utworzonych tablic dynamicznych możemy wprowadzać nowe elementy, a także usuwać elementy już istniejące. Co jednak najistotniejsze, możemy pozbyć się również całej tablicy, zwalniając tym samym zarezerwowaną dla niej pamięć. Taka praktyka jest wręcz zalecana w związku z charakterystyką przechowywania tablic dynamicznych – są one bowiem lokowane w stercie. Oznacza to, że po stronie programisty leży odpowiedzialność za zarządzanie danymi tablic, a więc również za uwalnianie zajętych przez nie bloków pamięci. Niektóre języki programowania oferują jednak mechanizmy „odśmiecania”, które m.in. zwalniają pamięć, co pozwala programiście na pominięcie tego procesu.
Podobnie jak wskaźniki, tablice dynamiczne również gwarantują wiele korzyści. Przede wszystkim zapewniają efektywniejsze i elastyczniejsze zarządzanie pamięcią podczas działania programu.
Niektóre języki programowania dostarczają zdefiniowane typy danych, pełniące funkcję tablicy dynamicznej o zmiennym rozmiarze. W języku C++ takim typem jest kontener vector, w języku Java natomiast jest nim kolekcja ArrayList.
Obiekty dynamiczne
Podobnie jak standardowe tablice statyczne mają swój dynamiczny odpowiednik, tak i obiekt może być dynamiczny. Pod pojęciem obiektu rozumiemy kluczową dla programowania obiektowego strukturę. Tworzenie takiego obiektu następuje nie w trakcie kompilacji, a podczas wykonywania programu z wykorzystaniem wskaźników. Rozwiązanie to umożliwia również dynamiczne zwolnienie pamięci, kiedy dany obiekt będzie już zbędny.
Zwolnienie pamięci przeznaczonej dla dynamicznego obiektu nie może być mylone z działaniem destruktora, który mimo usunięcia obiektu nie zwalnia pamięci dla niego przeznaczonej.
Oba rodzaje opisywanych struktur różnią się również typem pamięci, w której są przechowywane. Zazwyczaj obiekty statyczne umieszczane są w stosie, natomiast obiekty dynamiczne w stercie.
Słownik
ogólna zasada przetwarzania zasobów (cyfrowych lub fizycznych), zakładająca obsługiwanie w pierwszej kolejności tych elementów (a zarazem przekazanie ich na wyjście systemu), które jako ostatnie znalazły się na wejściu rozpatrywanego systemu
tablica, której rozmiar nie jest znany w momencie kompilacji, lecz określany w trakcie działania programu; taka tablica umożliwia nie tylko dodawanie do niej kolejnych elementów, ale także ich usuwanie; tablice dynamiczne mogą być również całkowicie usunięte przez programistę w celu zwolnienia zarezerwowanej dla nich pamięci (podobnie jak wskaźniki umożliwiają np. efektywniejsze wykorzystanie pamięci)
specjalna zmienna przeznaczona do przechowywania zawartego w pamięci adresu innej zmiennej; sam wskaźnik również przechowywany jest pod określonym innym adresem – jego wykorzystanie w programach może gwarantować liczne korzyści, np. efektywniejsze wykorzystanie zasobów pamięci
zmienne przechowujące adresy obiektów lub zmiennych typu prymitywnego; należą do nich np. tablice czy klasy
zmienne typu prymitywnego przechowują w pamięci konkretne wartości; przykład:
wartości te nie są obiektami