Przeczytaj
Projektowanie bazy
Naszym zadaniem jest zapisanie w bazie danych informacji potrzebnych podczas przyznawania studentom miejsc w akademikach. Oczywiście nie wszystkie informacje będą nas interesować. Potrzebujemy uproszczonego modelu, który będzie opisywał obiekt (studenta) i jego cechy. Ponieważ zajmujemy się relacyjnymi bazami danych, możemy odwołać się do modelu związków‑encjimodelu związków‑encji, który obiekty świata rzeczywistego określa właśnie mianem encjiencji, a ich powiązania – mianem związków.
Istotne dla nas będą następujące atrybuty encji:
Student |
|---|
imię |
nazwisko |
rok_studiów |
dochód_na_osobę_w_rodzinie |
Danych nie jest dużo – dotyczą one tylko jednego obiektu, więc do przechowywania ich w bazie wystarczy jedna tabela. Możemy ją schematycznie przedstawić tak:
Studenci |
|---|
id |
imie |
nazwisko |
rok_studiow |
dochod |
data_a |
aktywny |
W ten sposób stworzyliśmy najprostszy schemat bazy danych. Warto od razu zwrócić uwagę, że dodaliśmy trzy atrybuty. Pierwszy z nich, czyli unikalny identyfikator obiektu, nazywany najczęściej id, jest szczególnie ważny, ponieważ pełni rolę klucza głównego (ang. primary key)klucza głównego (ang. primary key). Drugie dodatkowe pole posłuży do przechowywania czasu dodania (aktualizacji) informacji, a trzecie pozwoli oznaczyć, czy student jest aktywny.
Przykładowa zawartość tabeli wygląda następująco:
Studenci | ||||||
id | imie | nazwisko | rok_studiow | dochod | data_a | aktywny |
|---|---|---|---|---|---|---|
1 | Adam | Słodowy | I | 2400.00 | 2019‑09‑18 12:15:48 | Tak |
2 | Ewa | Kowalska | I | 2300.00 | 2019‑09‑19 10:20:00 | Nie |
Definiowanie tabel
Instrukcje manipulujące bazą i tabelami należą do podgrupy poleceń języka SQL, zwanej skrótowo DDL (ang. Data Definition Language), czyli językiem definiowania danych. Polecenia z tej grupy to:
CREATE– tworzenie baz, tabel i indeksów,ALTER– zmiana struktury, np. dodanie kolumny, zmiana typu danych,DROP– usuwanie bazy, tabeli, indeksu.
Ogólna składnia polecenia tworzącego tabelę wygląda następująco:
W definicjach tabel obowiązują określone zasady składniowe:
definicje wszystkich pól wydzielamy okrągłymi nawiasami,
definicje pól wewnątrz nawiasów oddzielamy przecinkiem; dla przejrzystości możemy zapisywać je w nowych wierszach,
instrukcję
CREATEkończymy średnikiem.
Ze względów praktycznych warto przemyśleć nazwy kolumn. Np. wielowyrazowe nazwy zawierające małe i wielkie litery, spacje i znaki diakrytyczne możliwe są w programach typu LibreOffice Base lub Microsoft Access. Tymczasem w skryptach i przy wpisywaniu w wiersze poleceń baz danych tego typu, nazwy mogą sprawiać kłopoty ze względu na liczbę znaków potrzebnych do wpisania, konieczność specjalnego traktowania spacji czy problemy z kodowaniem znaków. Dlatego w nazwach tabel, zwłaszcza tych, które będziemy obsługiwać za pomocą skryptów i/lub wiersza poleceń, lepiej unikać polskich znaków, spacji oraz mieszania wielkich i małych liter.
Typy danych
Składnia polecenia tworzącego tabelę jest prosta – poważniejszym wyzwaniem są typy danych, których należy użyć do przechowywania informacji. Od ich właściwego wyboru zależy wydajność bazy, wynikająca między innymi z wielkości pamięci niezbędnej do przechowywania danych, jak i z czasu pracy procesora potrzebnego do wykonania operacji w bazie.
Zacznijmy od przeglądu dostępnych typów danych.
Przegląd oparto przede wszystkim na dokumentacji systemu bazodanowego MariaDB (otwartoźródłowa kontynuacja bazy MySQL).
Liczby całkowite
Podstawowym typem liczbowym całkowitym jest:
INT– liczba 4‑bajtowa, ; .
Omawiany typ ma wiele odmian różniących się rozmiarem wymaganej pamięci oraz zakresem wartości, np.: TINYINT, SMALLINT, MEDIUMINT czy BIGINT w wersji SIGNED (ze znakiem, domyślne) lub UNSIGNED (bez znaku).
Często używa się uniwersalnego typu INTEGER, który reprezentuje wszystkie omawiane typy.
Synonimem typu TINYINT jest BOOLEAN (BOOL), który służy do przechowywania wartości logicznych: True (prawda) – czyli wartość różna od zera – oraz False (fałsz), czyli wartość zero.
Typ INTEGER często występuje jako wartość klucza głównego. Może mieć wtedy atrybut AUTO_INCREMENT (baza MariaDB – MySQL) lub AUTOINCREMENT (baza SQLite3), który służy do generowania unikalnych identyfikatorów dla rekordów, poprzez zwiększanie poprzedniej wartości o 1. Pierwszy rekord ma zazwyczaj identyfikator 1.
Liczby zmiennoprzecinkowe
Typy zmiennoprzecinkowe także różnią się wielkością wymaganej pamięci oraz zakresem:
FLOAT– liczba 4‑bajtowa, pojedynczej precyzji, do 7 cyfr znaczących po separatorze,DOUBLE– liczba 8‑bajtowa, podwójnej precyzji, do 15 cyfr znaczących po separatorze,DECIMAL– liczba 8‑bajtowa, przechowywana w postaci znakowej, maksymalnie 65 cyfr, w tym 30 po separatorze dziesiętnym.
Synonimem typu DOUBLE jest REAL. Synonimy DECIMAL to DEC, NUMERIC i FIXED.
W typach zmiennoprzecinkowych możemy określić liczbę wszystkich cyfr oznaczaną literą M oraz dokładność jako liczbę miejsc po separatorze dziesiętnym, oznaczaną jako D, np. DECIMAL(6,3).
Typy FLOAT i DOUBLE zalecane są do przechowywania danych naukowych i wykonywania na nich obliczeń, natomiast dane finansowe powinny być zapisywane w polach typu DECIMAL.
Typy tekstowe
CHAR (M)– krótkie ciągi znaków (maks. 255) o stałej długości, ciąg krótszy niż zadeklarowany rozmiar pola uzupełniany jest spacjami;BINARY– typ podobny doCHAR, ale przechowuje wartości binarne;VARCHAR (M)– tekst o zmiennej długości, maksymalna liczba znaków zależy m.in. od kodowania, np. przy domyślnym kodowaniu UTF‑8 może to być 21844 znaków;TEXT (M)– tekst o maksymalnej długości 65535 znaków;BLOB (M)– pole tekstowe lub binarne o maksymalnej długości 65535 bajtów.
Opcjonalny parametr M pozwala wskazać liczbę znaków przechowywanych w polu. Różnice między typami VARCHAR i TEXT dotyczą indeksowania, wydajności oraz wykorzystania pamięci podczas zapisu i odczytu danych.
Typ TEXT ma odmiany różniące się maksymalną liczbą przechowywanych znaków: TINYTEXT, MEDIUMTEXT, LONGTEXT. Podobnie typ BLOB: TINYBLOB, MEDIUMBLOB, LONGBLOB.
Typy daty i czasu
Datę i czas możemy zapisywać i przechowywać w różnych formatach:
DATE– data w formacie YYYY‑MM‑DD może być zapisywana w różny sposób, np. 'YYYY‑M-DD', 'YYMMDD', 'YY*MM*DD',DATETIME– data i czas wyświetlane w formacie YYYY‑MM‑DD HH‑MM‑SS mogą być zapisywane jako znaki lub liczby, np. 'YY‑MM‑DD HH:MM:SS', YYYYMMDDHHMMSS,TIMESTAMP– typ wykorzystywany do zapisania czasu dodania lub aktualizacji rekordu; wartością jest liczba sekund, jaka upłynęła od początku epoki Uniksa, to jest od początku roku 1970 UTC; podczas tworzenia lub aktualizacji pola baza danych zapisuje aktualny czas uniksowy.
Jeżeli chcemy wskazać wartość domyślną dla pola TIMESTAMP w klauzulach DEFAULT i/lub ON UPDATE, możemy używać różnych synonimów czasu aktualnego akceptowanego w wybranym systemie bazodanowym, np. CURRENT_TIMESTAMP, CURRENT_TIMESTAMP(), NOW, NOW(), LOCALTIME, LOCALTIME().
Dobór typu danych w wielu systemach bazodanowych wpływa na wydajność (a nawet możliwość) przeprowadzania różnych operacji.
Dostępność, nazwy i charakterystyka typów danych zależy od systemu bazodanowego.
Większość systemów bazodanowych stosuje typowanie statyczne pole – z określonym typem wymaga wartości tego samego typu. SQLite3 dla odmiany stosuje system typowania dynamicznego, w którym ogólne klasy przechowywania (ang. storage classes) obejmują bardziej specyficzne typy danych, np. klasa INTEGER obejmuje sześć typów liczb całkowitych o różnej wielkości.
Wybór typów
Ogólna zasada mówi, że do przechowywania informacji wybieramy typ najprostszy, zajmujący najmniej pamięci, który może przechować przewidywany zakres wartości. Na przykład klucze główne w postaci liczb nie będą rosły w nieskończoność, więc zazwyczaj typ INT wystarczy – dla małych liczb można użyć typów TINYINT lub SMALLINT. Kod pocztowy to zdecydowanie typ CHAR, natomiast imię czy nazwisko – VARCHAR lub TEXT w zależności od systemu bazodanowego. W przypadku dat i czasu przetwarzanie TIMESTAMP jest efektywniejsze niż DATETIME, chociaż częściej stosowany jest ten drugi typ.
Przedstawione uwagi potraktujmy jako ogólne wskazówki, a użyty typ danych dostosujmy do przewidywanego użycia i konkretnego systemu bazodanowego.
Ograniczenia
Podczas definiowania pól nakładamy na nie ograniczenia (nazywane też właściwościami), które wyznaczają dodatkowe zasady przechowywania wartości w polu, np.:
PRIMARY KEY– (klucz główny) wskazuje, że wartość w polu jednoznacznie identyfikuje każdy rekord, czyli nie może się powtarzać; w obrębie tabeli może być tylko jedno takie pole;NOT NULL– wskazuje, że pole nie może zawierać wartościNULL;DEFAULT– definiuje domyślną wartość pola, np. '' – ciąg pusty;UNIQUE– oznacza, że wartości w polu nie mogą się powtórzyć, podobnie jak w kluczu głównym, ale w tabeli może być kilka kolumn z tym ograniczeniem;CHECK– wskazuje, że wszystkie wartości w polu spełniają podany warunek;INDEX– jest używane do szybkiego wyszukiwania danych w tabeli na podstawie pola z indeksowaniem.
Definiując pola, należy – jeśli to tylko możliwe – określać wartości domyślne. Dzięki temu podczas dodawania danych można pomijać część informacji, co przyśpiesza operację.
Dostępność poszczególnych ograniczeń zależy od systemu bazodanowego.
Baza danych i tabele w LibreOffice Base
Do utworzenia bazy danych oraz tabel użyjemy programu LibreOffice Base, będącego składnikiem wolnego i darmowego pakietu biurowego LibreOffice. W domyślnej instalacji program używa wbudowanego systemu bazodanowego HSQLDB w wersji 1.8, który do działania wymaga zainstalowanego środowiska uruchomieniowego języka Java (Java Runtime Environment).
Baza HSQLDB osadzona w LibreOffice Base ma pewne ograniczenia w porównaniu do tej samej bazy zainstalowanej na zewnętrznym serwerze. Najważniejszym jest brak obsługi wielu użytkowników i brak możliwości definiowania ich uprawnień. W kolejnych wersjach pakietu planuje się zastąpienie HSQLDB przez system bazodanowy Firebird. LibreOffice Base może obsługiwać wiele zewnętrznych systemów bazodanowych, w tym MariaDB (MySQL), SQL Server, Firebird czy SQLite3.
Do wykonania podanych poleceń potrzebna będzie nowa baza danych. Podczas jej tworzenia korzystamy z domyślnej opcji Osadzona HSQLDB. Baza powinna zostać zapisana w pliku o nazwie np. studenci.odb.
Polecenia będziemy wpisywać (lub wklejać) do okna, które wywołujemy, klikając w menu Narzędzia | SQL.
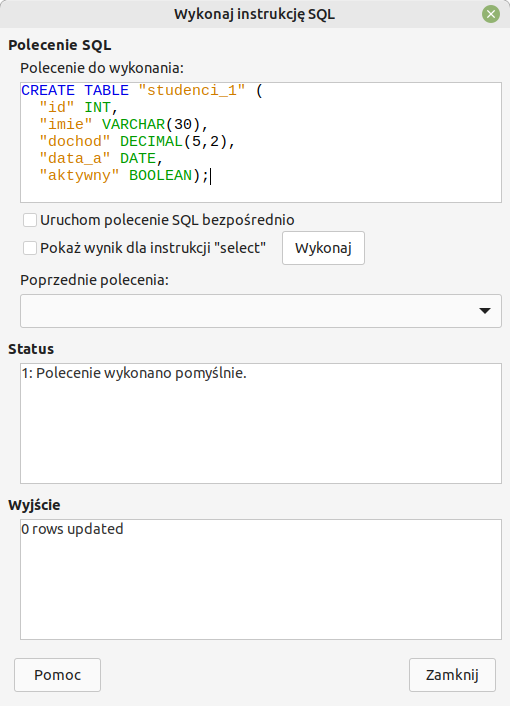
Podczas używania poleceń SQL należy zwrócić uwagę na dokładność wpisywanych lub wklejanych poleceń. Dotyczy to zwłaszcza typów używanych cudzysłowów oraz stosowania przecinków, nawiasów i średników.
W polu Polecenie do wykonania wpisujemy polecenie tworzące tabelę:
Po zamknięciu okna Polecenie SQL wybieramy z menu: Widok | Odśwież tabelę, aby zobaczyć utworzoną tabelę.
Tabelę studenci_1 warto otworzyć w trybie edycji i przejrzeć właściwości utworzonych pól, np. długość pola imie lub długość i dokładność pola dochod.
![Na ilustracji jest LibreOffice Base okno projektu tabeli. Są trzy kolumny: Nazwa pola, Typ pola, Opis. W nazwie pola jest id, w typie pola Integer [INTEGER]. W Nazwie pola wpisano imie, w typie pola: Tekst[VARCHAR]. W komórce Nazwy pola wpisano dochod, w typie pola Dziesietny[DECIMAL]. W Nazwie pola wpisano data a, w typie pola wpisano Data[DATE]. W Nazwie pola wpisano aktywny, w Typie pola wpisano Tak/Nie[BOOLEAN]. Komórki w ostatniej kolumnie są puste. Poniżej tabeli jest okienko: Właściwości pola. Poniżej jest Wpis wymagany: Nie. Długość: 5. Miejsca dziesiętne: 2.](https://static.zpe.gov.pl/portal/f/res-minimized/R1dGlUqbcryQK/1690815797/18c48w21L1PLwu9sx6FbNozSFTJ0f44s.png)
Wykonane polecenie pokazuje, jak tworzyć pola przechowujące podstawowe typy danych. W praktycznych zastosowaniach powinniśmy umieć definiować pole klucza głównego, a także nakładać ograniczenia, w tym definiować domyślne wartości pól. Zobaczmy, jak to robić.
Otwieramy okno Polecenie SQL i wpisujemy kod:
Tabela studenci utworzona za pomocą przedstawionego polecenia ma klucz główny (PRIMARY KEY) w postaci liczby całkowitej, której wartość będzie generowana automatycznie przez bazę, zaczynając od 0. Aby uzyskać taki efekt, musieliśmy użyć klauzuli IDENTITY wymaganej przez bazę HSQLDB.
Aby identyfikatory w polu klucza głównego zaczynały się od wartości 1, należy użyć definicji: "id" INTEGER GENERATED BY DEFAULT AS IDENTITY(START WITH 1,.
INCREMENT BY 1) PRIMARY KEY
Ponadto pola tekstowe nie mogą zawierać wartości NULL. W trzech ostatnich polach podaliśmy wartości domyślne, przy czym w polu data_a użyliśmy funkcji SQL NOW, która zwraca aktualny czas.
Sprawdźmy teraz, jak funkcjonują zdefiniowane kryteria. Wykonajmy następujące zapytanie:
INSERT INTO studenci(id, imie, nazwisko) VALUES(1, 'Adam', 'Słodowy');
Przedstawione polecenie warto wykonać dwa razy pod rząd – za drugim razem powinniśmy zobaczyć komunikat: Violation of unique constraint SYS_PK_49:.
duplicate value(s) for column(s) "id"
INSERT INTO "studenci" ("imie", "nazwisko") VALUES('Ewa', 'Kowalska');
W tym wypadku baza sama dobiera odpowiednią wartość klucza głównego, o czym możemy się przekonać, wydając polecenie:
SELECT * FROM "studenci";
Wyniki zapytania pokazują również, że pola, dla których nie podajemy wartości, przyjmują poprawne wartości domyślne, w tym również pole przechowujące czas.
Baza danych i tabele w Microsoft Access
Microsoft Access to zamkniętoźródłowy system obsługi relacyjnych baz danych wchodzący w skład pakietu Microsoft Office. Od wersji 2007 wykorzystuje silnik bazodanowy o nazwie Access Database Engine oraz Microsoft Access SQL, czyli implementację standardu ANSI SQL stworzoną przez Microsoft.
Między ANSI SQL i Microsoft Access SQL występują różnice w zakresie wspieranych typów danych, nazw typów danych i funkcji oraz składni.
Aby wykonywać polecenia SQL w Microsoft Access, tworzymy pustą bazę danych i zapisujemy w pliku o nazwie studenci.accdb. Po otwarciu bazy wybieramy wstążkę Tworzenie i klikamy ikonę Projekt kwerendy. Zamykamy okno Pokazywanie tabeli i klikamy ikonę SQL.
Jeżeli zostanie wyświetlone Ostrzeżenie o zabezpieczeniach, należy zezwolić na aktywną zawartość, klikając przycisk Włącz zawartość.
W oknie kwerendy wpisujemy następujące polecenia:
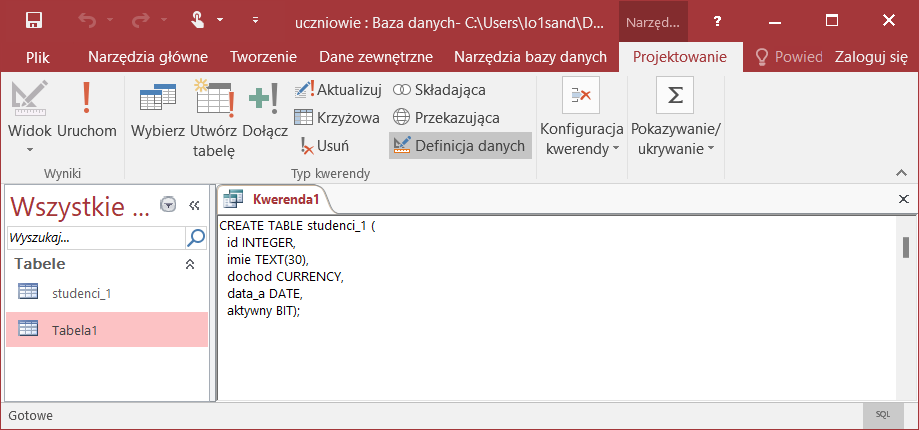
Wykonamy zapytanie, klikając ikonę Uruchom (z charakterystycznym czerwonym wykrzyknikiem). Po wykonaniu kwerendy na liście tabel powinna pokazać się nazwa studenci_1.
Utworzoną tabelę wyświetlimy w widoku projektu:
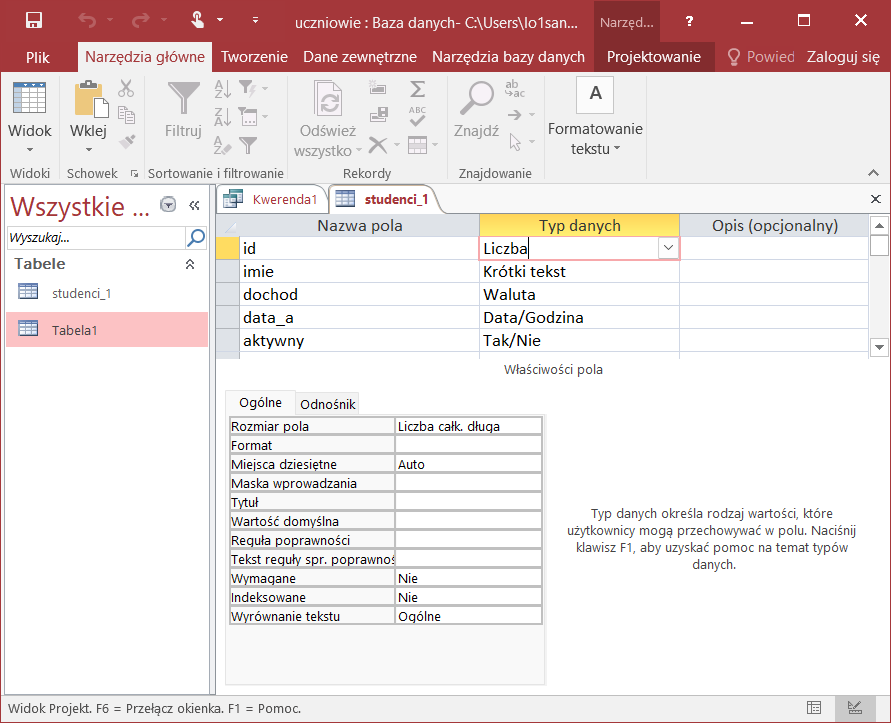
Microsoft Access wykorzystuje następujące typy danych:
TEXT(n)– typ przeznaczony dla krótkich tekstów do 255 znaków; w nawiasie podajemy długość pola, w widoku projektu toKrótki tekst;CURRENCY– typ do przechowywania wartości waluty; nie występuje w ANSI SQL, w widoku projektu toWaluta;DATETIME– typ przeznaczony na przechowywanie daty i czasu, w widoku projektu toData/Godzina;BIT– typ do przechowywania wartościPrawda/Fałsz, odpowiada typowi BOOLEAN, w widoku projektu to poleTak/Nie.
Wykonajmy teraz zapytanie, którego celem jest utworzenie tabeli studenci zawierającej klucz główny, a także ograniczenia NOT NULL nałożone na pola:
Po wykonaniu kwerendy w widoku projektu tabeli studenci możemy sprawdzić, że polu id został przypisany typ INTEGER, chociaż nie podaliśmy go wprost w zapytaniu. Z kolei dla pól imie i nazwisko, do których dodaliśmy ograniczenia, opcja Wymagane została ustawiona na Tak.
Wykonywanie zapytań DDL w oknie projektowania kwerendy ma spore ograniczenia. Np. obecność klauzuli DEFAULT w zapytaniu powoduje wyświetlenie komunikatu o błędzie składniowym, podobnie próba określania precyzji przy użyciu notacji DECIMAL(6,3).
Spróbujmy sprawdzić działanie nałożonych ograniczeń. Wykonajmy następujące zapytanie dwa razy:
Po pierwszym wykonaniu nie zobaczymy żadnego komunikatu, a w tabeli zostanie utworzony nowy rekord. Za drugim razem powinniśmy zobaczyć komunikat: „Program Microsoft Access nie może dołączyć wszystkich rekordów w kwerendzie dołączającej” oraz mało zrozumiałe wyjaśnienie powodów błędu.
Taki sam komunikat zobaczymy, gdy spróbujemy dodać rekord bez podania wartości wymaganych pól, np.:
Oznacza to, że ograniczenia NOT NULL działają we właściwy sposób.
Słownik
(ang. entity) schematyczny opis rzeczywistych lub wymyślonych obiektów posiadających te same cechy, zwane atrybutami lub własnościami
pole (lub kombinacja pól) zawierające niepowtarzalne wartości, jednoznacznie identyfikujące rekordy tabeli; najczęściej zawiera kolejne wartości liczbowe automatycznie tworzone przez aparat bazy danych
(ang. entity‑relationship model) logiczny model bazy danych opisujący obiekty świata rzeczywistego jako encje (ang. entities), a powiązania między nimi jako związki (ang. relationships)
(ang. constraints) dodatkowe warunki, które musi spełniać wartość przechowywana w kolumnie, np. NOT NULL
określa strukturę, rodzaj i zakres danych, które można przechowywać w danej kolumnie