Przeczytaj
Najprostszymi dynamicznymi strukturami, które poznaliśmy, są stos i kolejka. Obydwie implementować można za pomocą różnych mechanizmów. Jedno z najprostszych rozwiązań, które służy zazwyczaj do wyjaśnienia działania tych struktur w języku Python, to użycie listy, jednej z wbudowanych struktur danych. Jest to struktura dynamiczna umożliwiająca zapisywanie dowolnej liczby elementów. Z jej pomocą można łatwo implementować operacje wykonywane na omawianych poniżej strukturach. Ponieważ jednak celem tego materiału jest wyjaśnienie zasad działania i implementowania struktur dynamicznych, wykorzystywane dalej listy skonstruujemy sami przy użyciu klas użytkownika.
Stos
Przypomnijmy, że stos to liniowa struktura typu LIFO (ang. Last‑In, First‑Out – ostatni na wejściu, pierwszy na wyjściu), która obsługuje dwie podstawowe operacje, tj. odkładanie i zdejmowanie danych. Dodatkowe działania, które wykonuje się na stosie, to odczytywanie wierzchołka stosu, czyli ostatniego odłożonego elementu, bez usuwania go, oraz ewentualnie sprawdzanie rozmiaru stosu, czyli liczby odłożonych elementów.
W programie korzystamy z biblioteki sys.
Biorąc powyższe warunki pod uwagę, do implementacji stosu wystarczy nam jednokierunkowa lista niecykliczna. Elementami tej listy będą węzły zawierające dane, np. liczby, oraz – w przypadku listy jednokierunkowej – referencjareferencja na element następny. Do zdefiniowania węzła użyjemy klasyklasy zawierającej konstruktorkonstruktor inicjalizujący dwa pola klasy:
Stworzenie nowego węzła i przypisanie wartości do jego składowych umożliwia instrukcja:
Stos zaimplementujemy również jako klasę, której atrybutem inicjalizowanym w konstruktorze referencją pustąreferencją pustą będzie referencja na wierzchołek stosu o nazwie wierzcholek.
Do klasy Stos() dodamy teraz metody wykonujące charakterystyczne dla stosu operacje.
Zaczniemy od metody czyPusty(), która będzie zwracała wartość true (prawda), jeżeli stos będzie pusty, czyli w sytuacji, kiedy pole wierzcholek będzie referencją pustą. W przeciwnym razie metoda zwróci wartość false (fałsz).
W celu zachowania poprawności działania struktury LIFO, funkcja odloz() będzie dodawała elementy na początku listy i odpowiednio funkcja zdejmij() będzie usuwała elementy również z początku listy.
Zacznijmy od metody odloz():
W funkcji odloz() tworzymy nowy węzeł i zapisujemy w nim wartość zmiennej liczba przekazaną jako argument. Następnie pole nastepny nowego elementu ustawiamy na dotychczasowy wierzcholek, w ten sposób dodajemy element na początku listy. Na koniec aktualizujemy pole wierzcholek, tak aby wskazywało na nowo dodany element.
W metodzie pomijamy sprawdzenie ewentualnego błędu przepełnienia stosuprzepełnienia stosu, który ze względu na użycie listy jest mało prawdopodobny.
Usuwanie pierwszego elementu jest możliwe dzięki referencji wierzcholek:
Jeżeli stos jest pusty, tzn. zachodzi błąd niedopełnienia stosuniedopełnienia stosu, zwracamy minimalną wartość dla typu całkowitego, którą w języku wylicza się jako ujemną wartość maksymalną (-sys.maxsize) pomniejszoną o 1.
W przeciwnym razie dotychczasowy pierwszy element oraz zapisaną w nim wartość zapamiętujemy w zmiennych pomocniczych. Następnie ustawiamy wierzchołek na drugi element listy, dotychczasowy pierwszy usuwamy, a zapamiętaną wartość zwracamy.
Metoda pobierz_wierzcholek() ma tylko jedno zadanie: jeżeli stos nie jest pusty, zwraca wartość zapisaną w pierwszym, czyli ostatnim dodanym, elemencie listy:
Metoda wypisz() posłuży do wypisania wartości odłożonych na stosie, czyli zapisanych w kolejnych węzłach listy:
Do wypisania wartości używamy pętli przechodzącej po wszystkich elementach stosu zapisywanych w zmiennej pomocniczy, którą ustawiamy na wierzchołek, a następnie wewnątrz pętli przesuwamy na kolejne węzły wskazywane przez pole nastepny. Pętla będzie działać dopóki nie dojdziemy do ostatniego węzła, którego referencja nastepny będzie pusta.
Do sprawdzenia działania stosu możemy użyć poniższego kodu:
Na podstawie omówionego kodu przygotuj program ilustrujący działanie stosu. Przeanalizuj podaną funkcje główną i odpowiedz, jaki będzie ostatni wypisany przez program komunikat. Uruchom program i sprawdź poprawność swojej odpowiedzi.
Kolejka
Kolejka to liniowa struktura danych typu FIFO (ang. First‑In, First‑Out – pierwszy na wejściu, pierwszy na wyjściu), co oznacza, że jej elementy odczytywane są zgodnie z kolejnością dodawania, a zatem odwrotnie niż w przypadku stosu.
W implementacji kolejki również użyjemy listy jednokierunkowej i takiej samej jak w przypadku stosu definicji klasy Wezel. Natomiast klasa Kolejka będzie zawierała dwa pola:
glowa– referencję na pierwszy element kolejki;ogon– referencję na ostatni element kolejki, który ułatwi dodawanie elementów na końcu listy.
Nazwy pozostałych metod dostosujemy do omawianej struktury.
Metoda czy_pusta() działa tak samo, jak w przypadku stosu i każdej listy, tzn. jeżeli referencja na pierwszy element jest pusta, lista jest pusta.
Metoda dodaj() będzie dodawała nowe elementy na końcu listy przy użyciu pola ogon.
Na początku metody tworzymy nowy węzeł, przypisujemy otrzymaną liczbę do jego pola liczba, a referencję nastepny ustawiamy na wartość pustą. Następnie, jeżeli lista jest pusta, referencje na pierwszy (glowa) i ostatni (ogon) element listy ustawiamy na nowy węzeł.
W przeciwnym razie referencję nastepny dotychczasowego ostatniego elementu ustawiamy na nowy węzeł i aktualizujemy referencję ogon, aby wskazywał nowo dodany element.
Metoda usun() będzie zwracała kolejne elementy z początku listy, czyli działać będzie tak samo, jak metoda zdejmij() w przypadku stosu. Ponieważ jednak elementy będą dodawane na końcu listy, zasada działania kolejki FIFO zostanie zachowana.
Wykorzystaj omówiony kod i przygotuj program pozwalający sprawdzić działanie kolejki. Dodaj do kolejki trzy liczby, wypisz kolejkę, a następnie wywołaj metodę usuwającą cztery razy.
Lista
Przypomnijmy, że lista – podobnie jak stos i kolejka – jest liniową i dynamiczną strukturą danych. Elementami listy, jak już wiemy, są węzły, które zawierają dane oraz referencjęreferencję na element następny (w przypadku listy jednokierunkowej) lub na następny i poprzedni (w przypadku listy dwukierunkowej).
Do implementacji stosu i kolejki użyliśmy listy jednokierunkowej. Jej węzły zdefiniowaliśmy przy użyciu klasyklasy zawierającej konstruktor argumentowy inicjalizujący dwa pola:
Konstruktor wymaga podania argumentu podczas tworzenia obiektu, co pozwala zainicjować pole liczba otrzymaną wartością:
Lista jednokierunkowa
Listę jednokierunkową implementujemy jako klasęklasę z jednym polem glowa – referencją na pierwszy element listy. Oprócz tego w klasie definiujemy metody umożliwiające dodawanie, usuwanie i wypisywanie elementów listy. W konstruktorze __init__() inicjalizujemy pole glowa referencją pustąreferencją pustą.
Metody czy_pusta() oraz wypisz() działają tak samo jak w przypadku stosu i kolejki. Poniżej wyjaśnimy działanie metody dodającej węzły na końcu listy oraz usuwającej węzły o podanej pozycji.
Dodawanie węzłów na końcu listy jednokierunkowej
Metoda dodaj() jako argument będzie przyjmowała liczbę całkowitą. Nowy węzeł – inaczej niż w przypadku stosu i kolejki – będzie dodawany na końcu listy.
Na początku metody tworzymy nowy węzeł, przekazując do jego konstruktora otrzymaną liczbę. Następnie, jeżeli lista jest pusta, nowy węzeł staje się pierwszym elementem listy przypisanym do pola glowa.
W przeciwnym razie za pomocą węzła pomocniczy w pętli przechodzimy listę do ostatniego elementu, którego referencja nastepny będzie pusta. Po zakończeniu pętli pole nastepny dotychczasowego ostatniego elementu ustawiamy na nowy węzeł. W ten sposób dodajemy węzeł na końcu listy.
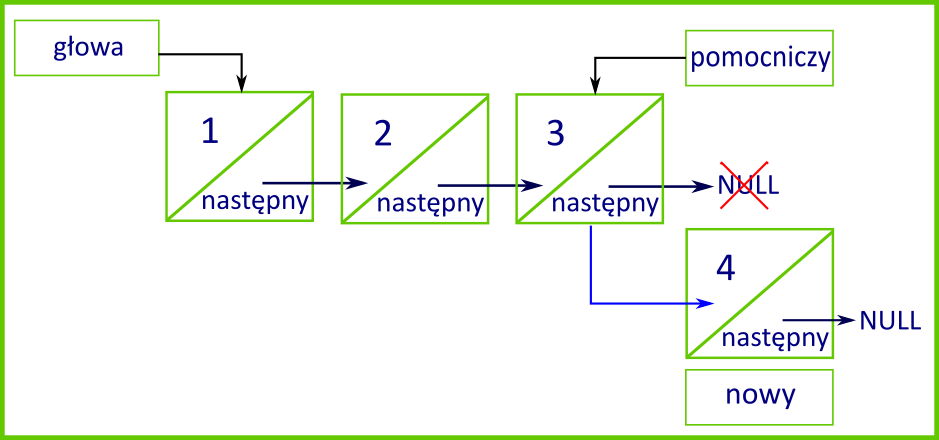
Usuwanie węzłów z listy jednokierunkowej
Metoda usuwająca węzły z listy otrzymywać będzie jako argument liczbę całkowitą wskazującą indeks czy też numer węzła, który chcemy usunąć. Przyjmijmy, że indeksy węzłów zaczynają się od 1.
Jeżeli lista nie jest pusta, definiujemy zmienne, których używamy w metodzie:
referencję
pomocniczy1ustawiamy na pierwszy element listy,referencję
pomocniczy2wykorzystamy przy usuwaniu węzłów innych od pierwszego,zmienna
rozmiarposłuży do ustalenia rozmiaru listy.
Następnie zliczamy elementy listy za pomocą pętli while przechodzącej po wszystkich węzłach listy, zaczynając od pierwszego. Po dojściu do ostatniego elementu w zmiennej pomocniczy1 zostanie zapisana wartość None i pętla zakończy swoje działanie.
Warto zapamiętać omówioną przed chwilą pętlę, ponieważ przechodzenie wszystkich elementów listy (zaczynając od pierwszego) jest typową operacją wykonywaną na listach.
Następnie, jeżeli podany indeks nie jest większy od obliczonego rozmiaru listy, zaczynamy usuwanie węzła. Zadanie to realizuje kod, który umieszczamy na końcu omawianej metody:
Jeżeli usuwanym elementem jest pierwszy węzeł (indeks 1), pole glowa ustawiamy na następny węzeł, co powoduje wyłączenie dotychczasowego pierwszego elementu z listy.
W przeciwnym razie w pętli, która wykonuje się, dopóki indeks jest większy od 1, szukamy węzła do usunięcia. W każdej iteracji indeks jest zmniejszany o 1 dzięki notacji postfiksowej. Wewnątrz pętli przechodzimy po indeks - 1 elementach listy od jej początku, więc po jej zakończeniu zmienna pomocniczy1 będzie wskazywała węzeł do usunięcia, a zmienna pomocniczy2 węzeł poprzedni.
Po zakończeniu pętli w węźle poprzedzającym węzeł usuwany ustawiamy referencję nastepny na węzeł następny po węźle usuwanym (w przypadku usuwania ostatniego węzła będzie to wartość None).
W językach programowania Python i Java nie trzeba usuwać węzła i zwalniać zajmowanej przez niego pamięci za pomocą osobnej instrukcji takiej jak np. wyrażenie delete() w języku C++. Jeżeli na jakiś obiekt nie wskazują żadne referencje, zostanie on usunięty przez mechanizm odśmiecania pamięci (ang. garbage collection).
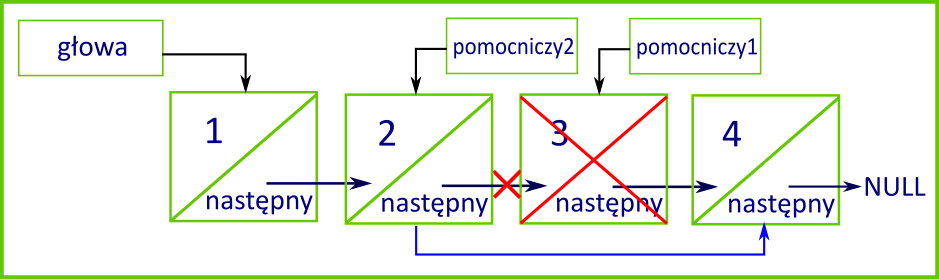
Wykorzystaj omówiony kod i przygotuj program pozwalający sprawdzić działanie listy jednokierunkowej. Dodaj do listy trzy liczby i wypisz listę. Następnie usuń drugi element i wypisz listę. Na końcu jeszcze raz usuń drugi element, dodaj liczbę i wypisz listę.
Lista dwukierunkowa
Lista dwukierunkowa od jednokierunkowej różni się tym, że jej węzły, oprócz referencji na element następny, zawierają także referencję na element poprzedni. Implementację przygotujemy w oparciu o omówiony kod listy jednokierunkowej.
Na początku uzupełniamy klasę Wezel o pole poprzedni i uzupełniamy konstruktor tak, aby inicjalizował je wartością pustą. Do klasy Lista dodajemy pole ogon, które będzie wskazywało ostatni element listy. W konstruktorze klasy pola glowa i ogon ustawiamy na wartości puste.
Pole ogon, tj. referencja na ostatni element listy, jest opcjonalne, może występować zarówno w listach jedno-, jak i dwukierunkowych. Używa się go m.in. do szybkiego dodawania elementów na końcu listy bez konieczności przechodzenia po wszystkich jej elementach w celu znalezienia ostatniego.
Dodawanie węzłów na końcu listy dwukierunkowej
Metody czy_pusta() oraz wypisz() pozostają bez zmian. Modyfikacji wymagają tylko implementacje metod dodaj() i usun(). Zacznijmy od metody dodającej nowe węzły:
Różnice w porównaniu do implementacji tej metody w przypadku listy jednokierunkowej są następujące:
ustawienia pola
ogonna nowy węzeł w przypadku dodawania pierwszego elementu listy,wykorzystanie pola
ogon– zamiast pętli przechodzącej wszystkie elementy listy – do wskazania ostatniego węzła listy,ustawienie referencji
nastepnydotychczasowego ostatniego węzła na nowy orazpoprzedninowego węzła na dotychczasowy ostatni,ustawienie pola
ogonna nowo dodany element.
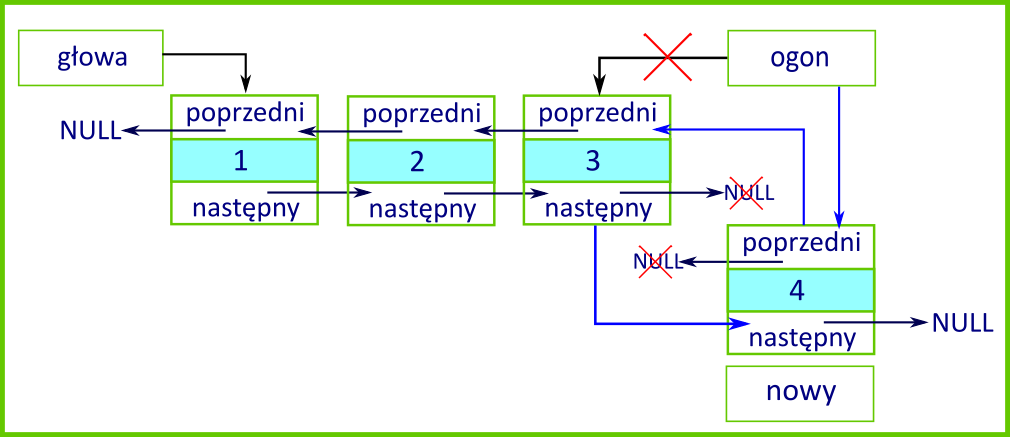
Usuwanie węzłów z listy dwukierunkowej
Metoda usuwająca elementy z podanej pozycji nie wymaga zmian, lecz uzupełnienia. Jeżeli usuwamy element niebędący ani pierwszym, ani ostatnim, musimy odpowiednio ustawić referencję poprzedni węzła występującego po węźle usuwanym. W przeciwnym razie, jeżeli usuwamy ostatni element, musimy zaktualizować pole ogon, aby wskazywało na dotychczasowy węzeł przedostatni. Poniżej kod uzupełnionej metody usun(). W komentarzu zaznaczyliśmy instrukcję warunkową realizującą omówione operacje:
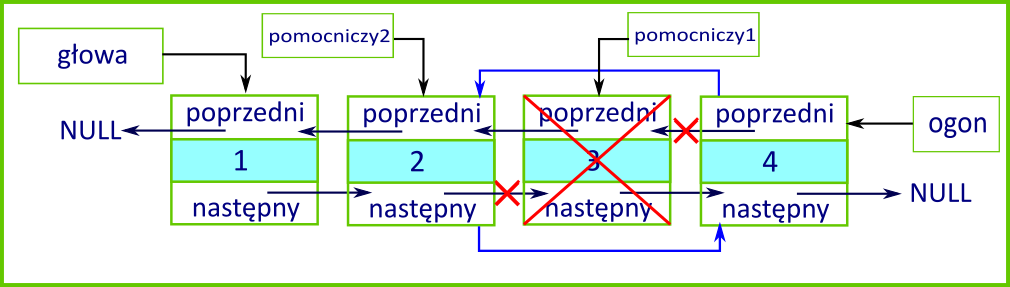
Wykorzystaj omówiony kod i przygotuj program pozwalający sprawdzić działanie listy dwukierunkowej. Dodaj do listy trzy liczby i wypisz listę. Następnie usuń pierwszy, drugi i trzeci element. Dodaj do listy jeszcze jedną liczbę i wypisz listę.
Klasa deque z modułu collections
Jak zaznaczyliśmy na początku materiału, jedną z podstawowych struktur danych wbudowanych w język Python jest lista. Jest to struktura dynamiczna ogólnego zastosowania i może służyć do implementacji stosu czy kolejki, jednak pamiętać należy, że listy w Pythonie optymalizowane są dla struktur o stałych rozmiarach.
Jeżeli więc zmierzamy korzystać ze struktur, w których liczba elementów często się zmienia, użyć należy klasy deque z modułu collections. Nazwa klasy jest skrótem od angielskich słów double‑ended queue, co oznacza kolejkę dwukierunkową. Klasa implementuje wyspecjalizowany kontener oferujący zoptymalizowane operacje dodawania i usuwania elementów z początku i końca struktury.
Klasa deque udostępnia m. in. następujące metody:
append()– zadaniem metody jest dodawanie elementu na końcu listy;pop()– metoda zwraca ostatni element listy i go usuwa;appendleft()– zadaniem metody jest dodawanie elementu na początku listy;popleft()– metoda zwraca pierwszy element listy i go usuwa.
Pozostałe funkcjonalności danej struktury (oznaczonej poniżej nazwą s) uzyskujemy za pomocą standardowych mechanizmów języka. Możemy używać następujących instrukcji:
len(s)– instrukcja zwraca liczbę elementów listy;s[0]– zadaniem instrukcji jest zwrócenie bez usuwania pierwszego elementu listy;s[-1]lubs[len(s) - 1]– zadaniem instrukcji jest zwrócenie bez usuwania ostatniego elementu listy;if s:,while s:,return s– instrukcja sprawdza, czy lista jest pusta; jeśli tak,sprzyjmie wartośćFalse, w przeciwnym razieTrue.
Kontener deque jako stos
Elementy stosu dodawane będą na końcu struktury i odczytywane będą również od końca, w ten sposób zachowana zostanie zasada LIFO.
Przykładowy program:
Na początku tworzymy obiekt stos i odkładamy trzy liczby za pomocą metody append(), która dodaje je na końcu. Następnie wypisujemy rozmiar (len(stos)) i wierzchołek (stos[-1]) stosu.
W kolejnych instrukcjach zdejmujemy wierzchołek ze stosu (pop()), wypisujemy rozmiar i nowy wierzchołek.
W pętli (while stos:) wykonującej się, dopóki stos nie jest pusty, zdejmujemy i wypisujemy kolejne wierzchołki. Na końcu wypisujemy jeszcze raz aktualny rozmiar stosu.
Wynik działania programu:
Kontener deque jako kolejka
Elementy kolejki dodawane będą na końcu struktury, ale odczytywane będą od początku, w ten sposób zachowana zostanie zasada FIFO.
Przykładowy program:
Na początku tworzymy obiekt kolejka i dodajemy trzy liczby (append()), po czym wypisujemy rozmiar (len(kolejka)), pierwszy (kolejka[0]) i ostatni (kolejka[-1]) element.
Następnie usuwamy pierwszy element (popleft()) i ponownie wypisujemy rozmiar, pierwszy i ostatni element.
W pętli (while kolejka:) wykonującej się, dopóki kolejka nie jest pusta, usuwamy i wypisujemy kolejne pierwsze elementy. Na końcu wypisujemy jeszcze raz aktualny rozmiar kolejki.
Wynik działania programu:
Kontener deque jako lista
Przykładowy program:
Na początku tworzymy obiekt lista i dodajemy dwie liczby (append()), następnie jedną na początku (appendleft()), po czym wypisujemy rozmiar (len(lista)) oraz pierwszy (lista[0]) i ostatni (lista[-1]) element.
Następnie usuwamy ostatni element (pop()) oraz ponownie wypisujemy rozmiar, pierwszy i ostatni element listy.
W pętli (while lista:) wykonującej się, dopóki lista nie jest pusta, usuwamy i wypisujemy kolejne pierwsze elementy (popleft()). Na końcu wypisujemy jeszcze raz aktualny rozmiar listy.
Wynik działania programu:
Słownik
definiowany przez użytkownika złożony typ danych, który pozwala grupować logicznie powiazane dane oraz funkcje wykonujące na nich operacje; składowe klasy nazywamy polami, funkcje zdefiniowane w klasie nazywa się metodami
metoda o takie samej nazwie jak klasa, która służy do nadawania wartości początkowych jej polom; w języku C++ klasa może mieć wiele konstruktorów dzięki mechanizmowi przeciążania
(ang. stack underflow) – rodzaj błędu występującego kiedy program próbuje zdjąć wartość z pustego stosu.
(ang. stack overflow) – rodzaj błędu polegającego na przekroczeniu rozmiaru pamięci zarezerwowanej dla stosu.
zmienna zawierająca informacje o położeniu jakiejś wartości (obiektu) w pamięci; referencje zarządzane są przez kompilator lub interpreter, a nie przez programistę, dzięki czemu są bezpieczniejsze niż wskaźniki; referencje mogą być puste, co znaczy, że nie wskazują na żaden obiekt, w języku Java wyraża to wartość null, w języku Python None
zmienna przechowująca adres innej zmiennej lub obiektu, pozwalająca na bezpośredni dostęp do pamięci; możliwe jest tworzenie wskaźników pustych, które na nic nie wskazują