Przeczytaj
Optymalizacja algorytmów sortowania
W jednym z poprzednich e‑materiałów omawialiśmy zagadnienie optymalizacji algorytmów sortowaniasortowania. Polega ona na doprowadzeniu do uzyskania możliwie najbardziej wydajnego algorytmu. W procesie optymalizacji staramy się zazwyczaj ograniczyć liczbę zbędnych operacji. Przekłada się to na zmniejszenie pamięciowej i czasowej złożoności obliczeniowej algorytmu.
Istotą optymalizacji algorytmów nie jest opracowywanie całkowicie nowych metod porządkowania danych, lecz usprawnianie mechanizmów już znanych. Cały proces ma jednak również pewien związek z tworzeniem alternatywnych algorytmów. Część spośród nich bazuje na gotowych rozwiązaniach bądź czerpie niektóre z ich elementów. Optymalizacja miewa zatem także własny wkład w nowe sposoby sortowania.
Alternatywne metody sortowania
Powody, dla których opracowuje się alternatywne metody sortowania, mogą być przeróżne – rozpoczynając od chęci zaprojektowania dobrego, zdatnego do użytku algorytmu, a kończąc na dążeniach do rozwiązania jakiegoś problemu matematycznego. Niezależnie od pobudek autorów, analizowanie oraz testowanie przedstawionych mechanizmów daje szansę na dokonanie ciekawych obserwacji oraz wyciągnięcia z nich wniosków (a może także przyczynić się do powstania kolejnego nietypowego algorytmu).
Alternatywne sposoby porządkowania danych dobrze jest poznać nawet wtedy, gdy algorytmy sortowania uważamy wyłącznie za narzędzia przydatne podczas pisania programów. Istnieje spore prawdopodobieństwo, że nietypowe, rzadziej stosowane i mniej znane metody okażą się zdatne do efektywnego wykorzystania w obecnych bądź przyszłych projektach. Z tego właśnie powodu przeanalizujemy trzy różne algorytmy porządkowania danych: algorytm kopcowy, naleśnikowy oraz bogosort.
Sortowanie kopcowe
Algorytm sortowania kopcowego (nazywanego też sortowaniem przez kopcowanie lub sortowaniem stogowym) jest algorytmem niestabilnym. Podczas jego wykonywania konstruowany jest pojawiający się w nazwie kopiec, będący w rzeczywistości drzewem binarnymdrzewem binarnym.
Załóżmy, że chcemy posortować nierosnąco zbiór {5, 8, 4, 11, 6, 9, 1}. Pierwszy element umieszczamy na samej górze stogu (możemy go również nazwać korzeniem drzewa binarnego).
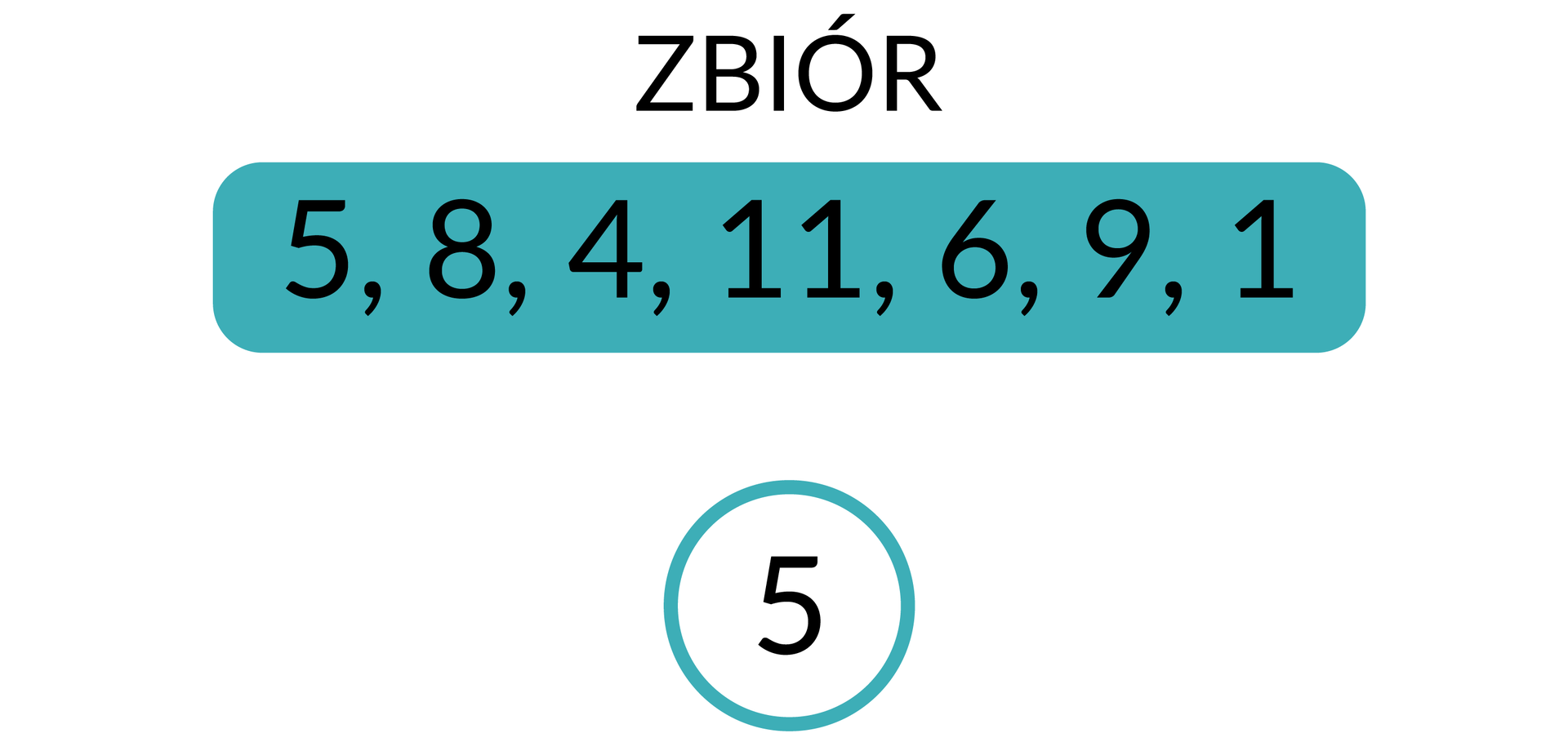
Poniżej szczytu kopca umieszczamy kolejny element zbioru. Porównujemy wartość górnego (tzw. nadrzędnego) węzła kopca z wartościami węzłów położonych niżej (tzw. potomnych węzłów kopca). Obowiązuje przy tym następująca zasada: jeżeli element znajdujący się na górze jest większy od elementu umieszczonego niżej, nie zmieniamy ich ułożenia. W przeciwnym przypadku zamieniamy elementy miejscami.

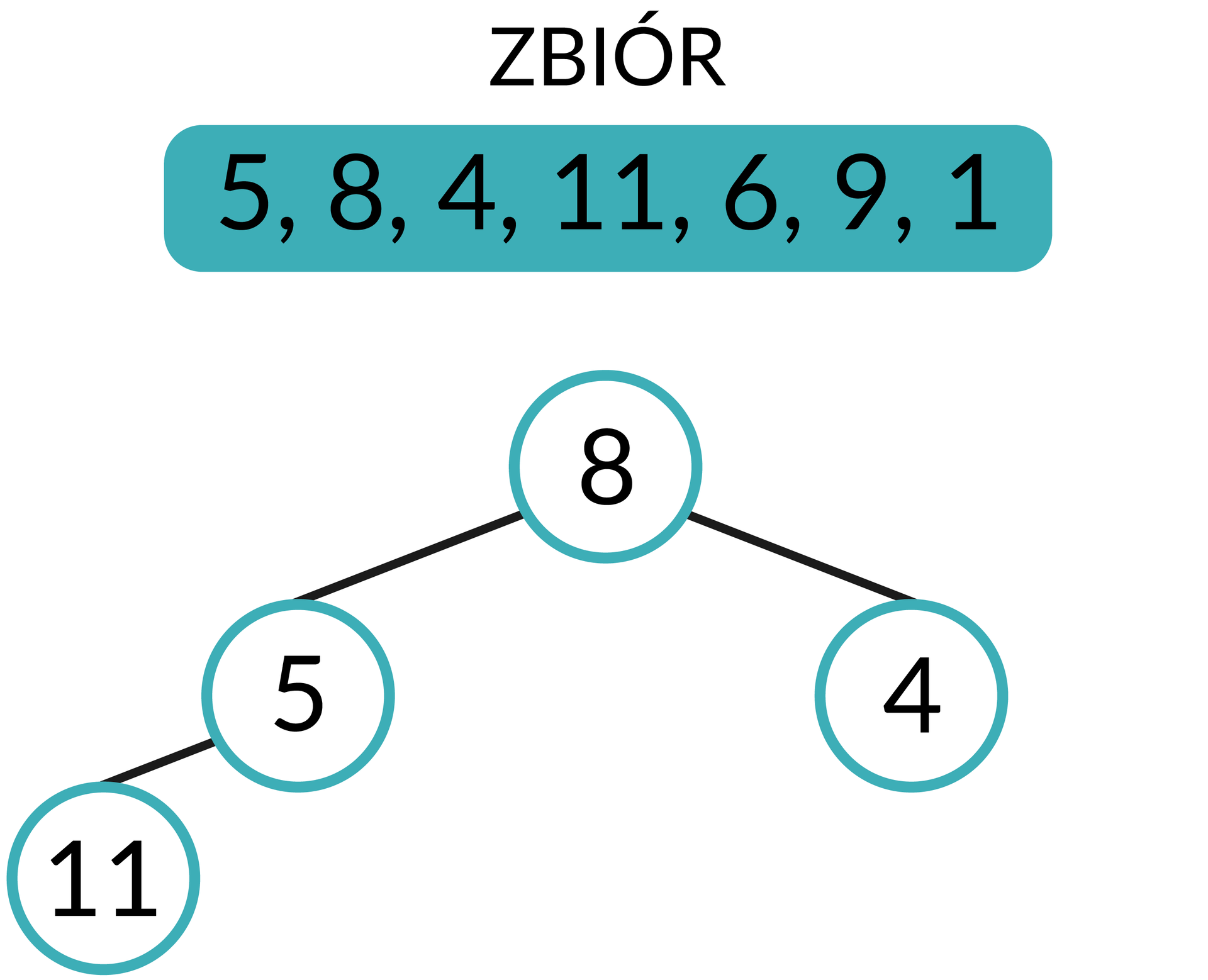
Liczba 8 jest większa niż 5, dlatego nastąpi zamiana miejsc.

Każdy węzeł nadrzędny ma dwa węzły potomne. Kolejny element zbioru umieścimy zatem na tym samym poziomie, na którym znajduje się obecnie element o wartości 5. Również i w tym wypadku sprawdzimy, czy zachowana jest przedstawiona wcześniej zasada.

Opisane czynności wykonujemy aż do wykorzystania wszystkich elementów zbioru. Na kolejnych obrazkach przedstawione zostały działania podejmowane przy dodawaniu liczby 11 do kopca.
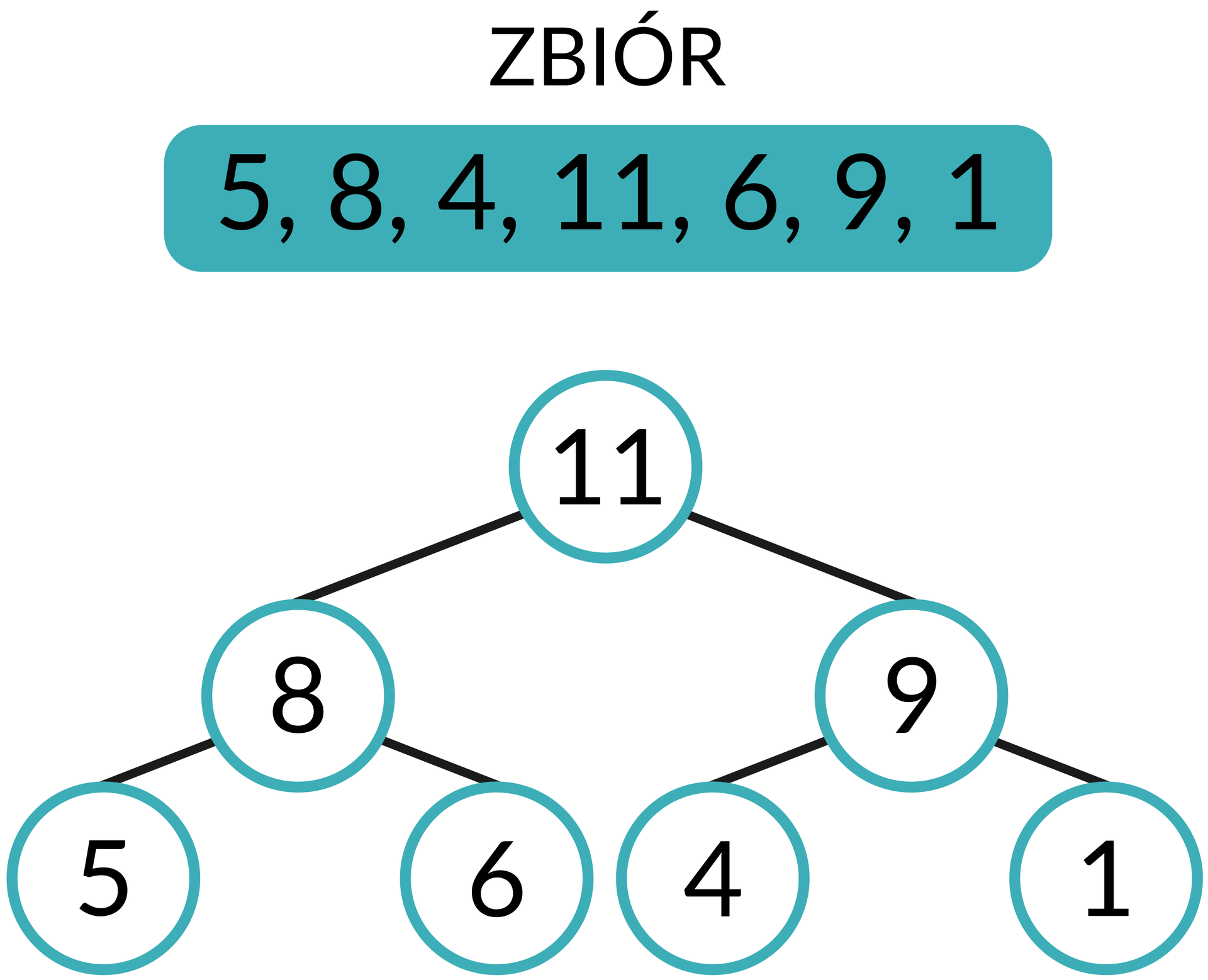
Liczba 11 jest większa od 5, musimy więc zamienić je miejscami.

Liczba 11 jest również większa niż znajdująca się w węźle nadrzędnym liczba 8; ponownie zamieniamy więc elementy.

Po wykonaniu podobnych operacji na następnych elementach zbioru otrzymamy całe drzewo.
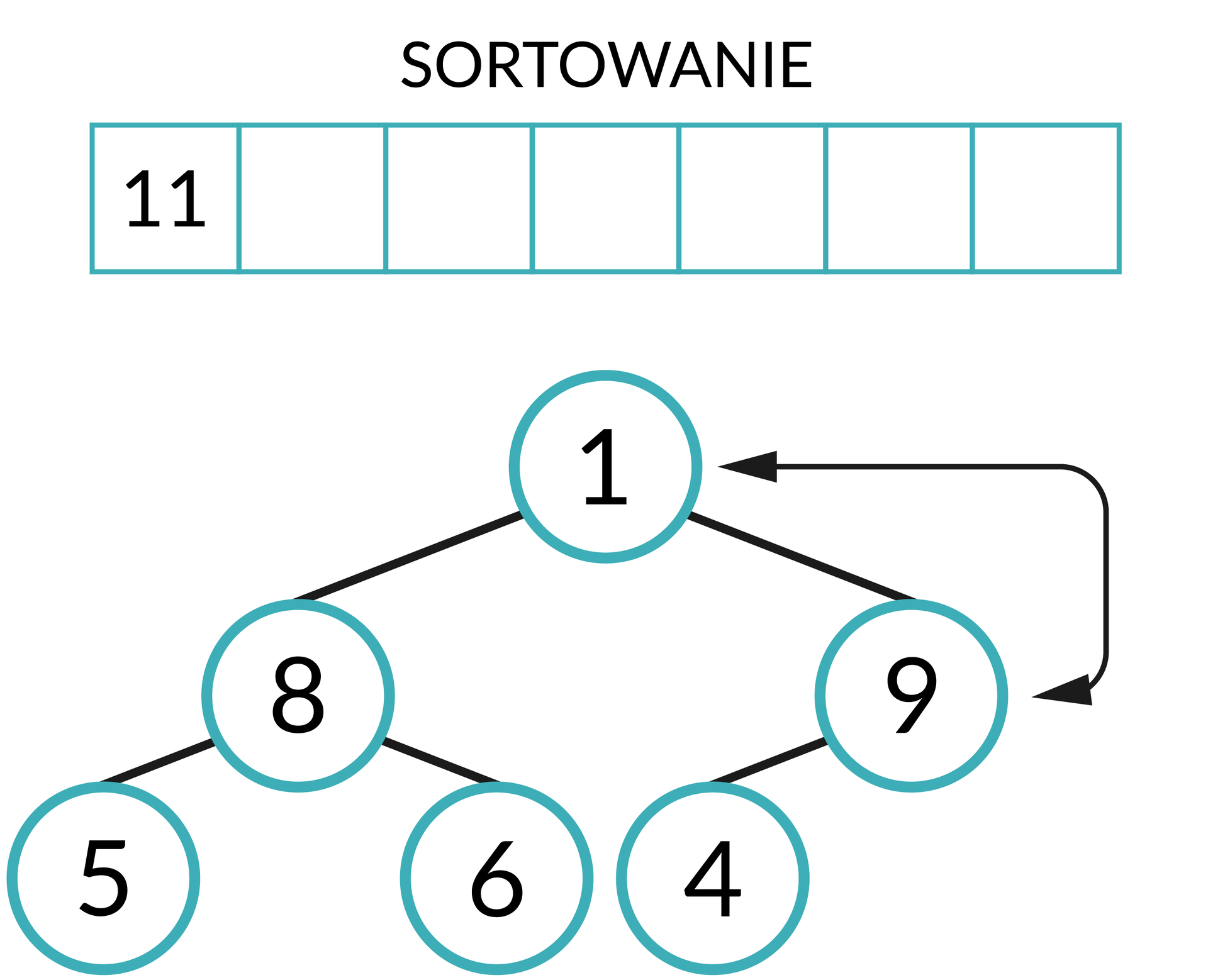
Teraz należy zmienić budowę kopca. Popularną metodą jest przepisanie do pustego zbioru wartości elementu ze szczytu stogu, a następnie usunięcie go z kopca i zastąpienie ostatnim elementem (znajdującym się najdalej z prawej strony w najniższym rzędzie węzłów).


Musimy ponownie uporządkować stóg zgodnie z przedstawioną wcześniej zasadą. Po wykonaniu niezbędnych operacji na szczycie stogu znowu pojawi się największa obecnie liczba.


Czynności składające się na algorytm będziemy powtarzać do momentu, gdy wykorzystamy wszystkie węzły, a cały kopiec zniknie. Kolejne wartości umieszczane na szczycie kopca zapisujemy w zbiorze wynikowym przed ostatnio dodanymi elementami lub za nimi – w zależności od tego, czy chcemy posortować dane rosnąco, czy malejąco.
Sortowanie kopcowe można wykonać, konstruując drzewo binarne przy odwrotnym założeniu: węzły zmieniamy miejscami, gdy wartość w węźle nadrzędnym będzie większa lub równa wartości w węźle podrzędnym.
Warto zaznaczyć, że sortowanie przez kopcowanie jest efektywne pod względem pamięciowym oraz czasowym: jego pamięciowa i pesymistyczna czasowa złożoność obliczeniowa wynosi odpowiednio O(n) i O(n log n).
Sortowanie naleśnikowe
Sortowanie naleśnikowe, w przeciwieństwie do sortowania przez kopcowanie, nie jest typową metodą porządkowania danych, lecz raczej problemem matematycznym. Zakładamy, że dysponujemy kuchenną łopatką, za pomocą której musimy posortować ułożone jeden na drugim naleśniki o różnych rozmiarach. Wykorzystywany przyrząd możemy włożyć pomiędzy dwa dowolne naleśniki lub pod naleśnik znajdujący się na samym dole, a następnie przewrócić do góry nogami całą, znajdującą się nad łopatką stertę.


W odróżnieniu od typowego problemu związanego z sortowaniem nie interesuje nas liczba przeprowadzonych porównań, a jedynie minimalna liczba operacji łopatką wymagana do posortowania naleśników według ich rozmiaru. Bazując na liczbie naleśników, będziemy w stanie określić złożoność obliczeniową algorytmu. Jej analizę wykonamy dla prostej wersji sortowania naleśnikowego polegającej na wyszukiwaniu aktualnie największego, nieposortowanego jeszcze naleśnika i umieszczeniu go na szczycie stosu, a następnie wykonaniu kolejnego przewrócenia tak, aby naleśnik znalazł się na pożądanym miejscu. Jako optymistyczny wariant sortowania założyć możemy scenariusz, w którym wszystkie naleśniki są od razu posortowane. Wówczas zbędne będą jakiekolwiek operacje łopatką, a złożoność czasowa wyniesie O(n) (n to liczba naleśników na stosie). W pesymistycznym przypadku na stercie ułożone będą na przemian kolejno naleśnik najmniejszy i największy. Wariant ten przedstawiony za pomocą zbioru liczb mógłby wyglądać następująco {0, 6, 1, 5, 2, 4, 3}. W takiej sytuacji wymagana liczba przewrotów naleśników określana jest jako 2n‑3, a również i sama złożoność czasowa ulegnie zmianie. Złożoność O(n) mogliśmy rozumieć jako czas wymagany na przewrócenie n naleśników. W przypadkach innych niż optymistyczny musimy jednak uwzględnić również czas przeznaczony na szukanie największego naleśnika. W wariancie pesymistycznym będziemy musieli przeszukiwać cały stos naszych naleśników przed wykonaniem operacji łopatką. Przy takim założeniu nasza złożoność czasowa wyniesie O(nIndeks górny 22).
Dodatkowo warto nadmienić, że sortowanie naleśnikowe nie wymaga żadnej pamięci pomocniczej, dlatego złożoność pamięciowa określana jest jako O(n).
Problem sortowania naleśnikowego po raz pierwszy opisał amerykański matematyk Jacob E. Goodman, a w jego rozwiązanie zaangażował się między innymi Bill Gates.
Bogosort
Bogosort (znany również jako slow sort lub stupid sort) jest algorytmem sortowania w pełni bazującym na losowości. Jego działanie jest proste w założeniach i polega na losowaniu ustawień sortowanych elementów, aż do uzyskania całkowicie posortowanego zbioru. Jest to metoda wysoce nieefektywna i nie nadaje się do praktycznego zastosowania. W wariancie pesymistycznym pełne posortowanie całego zbioru może nigdy nie nastąpić.
Wyobraźmy sobie następującą sytuację: przypadkowo ustawiamy wszystkich uczniów naszej szkoły w jednym rzędzie, a następnie pytam się każdego z nich po kolei o datę urodzenia. Szansa, że uda nam się uzyskać kolejność uczniów w rzędzie od najmłodszego do najstarszego jest niewyobrażalnie mała, nawet w przypadku, gdy nasza szkoła nie należy do największych placówek edukacyjnych. Tego typu przykład idealnie obrazuje nam wspomnianą nieefektywność algorytmu bogosort.
Opisywana metoda nie jest jednak całkowicie bezużyteczna. Może być dobrym, edukacyjnym porównaniem dla skuteczniejszych i popularniejszych metod sortowania.
Słownik
drzewo, którego każdy węzeł (wierzchołek) ma maksymalnie dwa węzły potomne (dwóch synów)
proces polegający na porządkowaniu zbioru elementów według ich wybranych cech