Kolejka
Kolejka
Każdy z nas miał do czynienia z kolejkąkolejką w sklepie. Zasada jej działania jest dosyć prosta: osoba, która znajduje się przed nami, pojawiła się wcześniej, a więc zostanie wcześniej obsłużona. Tak samo działa struktura danych zwana kolejką.
Kolejka jest przeciwieństwem stosu, jeśli chodzi o sposób dodawania i usuwania elementów. Nazywamy ją strukturą typu FIFO (z ang. First In First Out, czyli „pierwszy na wejściu, pierwszy na wyjściu”). Nowy element jest dodawany na końcu kolejki. Natomiast jako pierwszy usuwany jest element z początku kolejki.
Kolejka może być wykorzystana np. w teorii grafów w algorytmie przeszukiwania grafu wszerz.
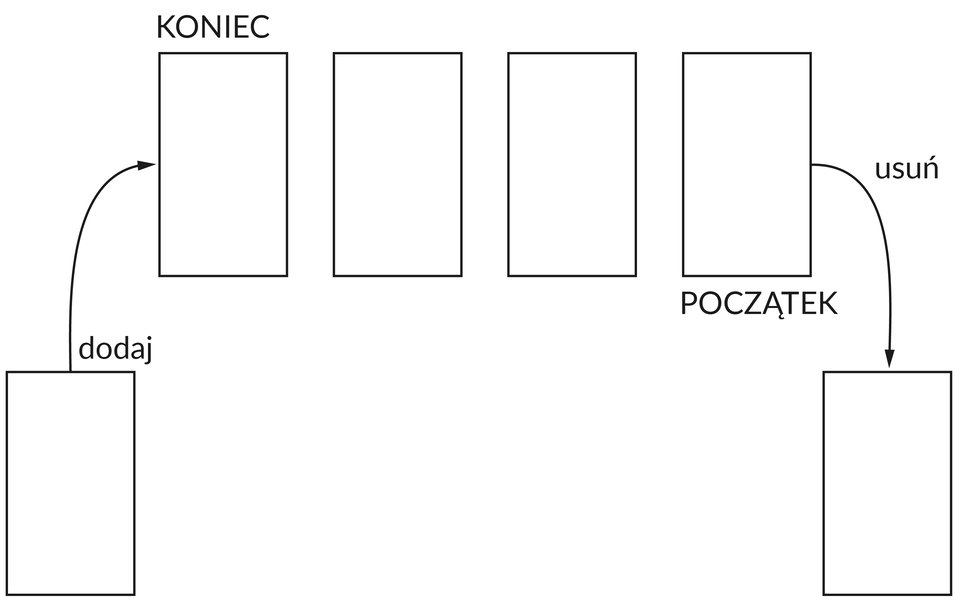
Tak jak w przypadku stosu, nie możemy użyć indeksowania, aby odwołać się do dowolnych elementów składających się na kolejkę. Jesteśmy w stanie tylko odczytać wartości znajdujące się na jej początku.
Implementacja kolejki z zastosowaniem tablicy
Kolejka także jest strukturą dynamiczną, lecz możemy ją zaimplementować, używając statycznej tablicy. Jedynym ograniczeniem jest maksymalna liczba przechowywanych w kolejce elementów.
Aby kolejka działała poprawnie, konieczne jest użycie dwóch zmiennych. Jedna z nich będzie wskazywała początek kolejki, natomiast druga jej koniec.
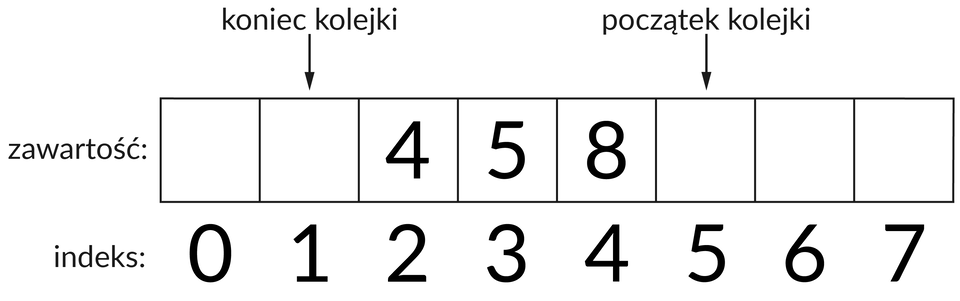
Poniżej znajdują się zapisane za pomocą pseudokodu funkcje wykorzystywane podczas dodawania i usuwania elementów kolejki. Zakładamy, że kolejka jest reprezentowana przez tablicę kolejka o rozmiarze elementów. Indeksy początku oraz końca kolejki są przechowywane w postaci zmiennych indeks_poczatek oraz indeks_koniec. Początkowa wartość indeks_poczatek wynosi . Zmienną indeks_koniec inicjalizujemy z kolei wartością o jeden mniejszą, czyli . Tablicę indeksujemy od wartości .
Przedstawiony za pomocą pseudokodu program może wydawać się skomplikowany, ponieważ zawiera dużo instrukcji warunkowych. Odpowiadają one za przesuwanie indeksów wskazujących krańce kolejki z początku na koniec tablicy. Dzięki temu nigdy nie wychodzimy poza zakres tablicy w wyniku modyfikacji indeksów.
Dodatkowo indeks_poczatek zawsze wskazuje indeks komórki tablicy za pierwszym elementem. Jest to pewne ułatwienie, które pomaga stwierdzić, kiedy kolejka jest pełna, a kiedy pusta. Jego wadą jest to, że kolejka może przechowywać nie , lecz elementów. Aby dokładniej zrozumieć, dlaczego tak się dzieje, pomocne mogą okazać się aplety dostępne w sekcji „Aplet”, których zadaniem jest wizualizowanie działania kolejki.
Istnieje również wariant kolejki nazywany kolejką priorytetową. Charakteryzuje się ona tym, że elementy znajdujące się w kolejce są zawsze posortowane. W rezultacie na początku kolejki zawsze znajduje się najmniejszy bądź największy element.