Przeczytaj
Dlaczego instrukcja warunkowa nie zawsze wystarcza?
Standardowa instrukcja warunkowa sprawdza się doskonale, kiedy wystarczy dokonać wyboru między dwoma zestawami poleceń zapisanymi w kodzie programu. Decyzję podejmuje się na podstawie tego, czy określony przez programistę warunek został spełniony, czy też nie.
Sprawy komplikują się, gdy należy wziąć pod uwagę zrealizowanie więcej niż dwóch odmiennych scenariuszy. Na wstępie lekcji posłużyliśmy się przykładem automatu do sprzedaży napojów. Ten sam problem pojawia się w wielu innych przypadkach – jak choćby w aplikacjach sterujących interfejsami bankomatów. Pozwalają one użytkownikowi wskazać kilka standardowych kwot do wypłacenia, a na dodatek samodzielnie określić oczekiwaną sumę pieniędzy.
Zastosowanie w takim przypadku instrukcji warunkowej jest możliwe, ale nastręcza kłopotów podczas tworzenia algorytmu. Ponieważ da się wówczas wziąć pod uwagę tylko dwa scenariusze, trzeba budować skomplikowane, kaskadowe konstrukcje: jeżeli... to... – jeżeli... to... –jeżeli... to..., itd. Takie zagnieżdżone sekwencje poleceń szybko stają się trudne do zrozumienia.
Znacznie bardziej przejrzyste i wygodne w użyciu okazują się instrukcje wielokrotnego wyboru, dostępne w wielu językach programowania – przykładowo, w języku C++ czy Java.
Czym jest wybór wielokrotny?
Dzięki wyborowi wielokrotnemu da się zapisać różne sekwencje poleceń (scenariusze zdarzeń), które powinny być obsługiwane przez program, a następnie wybierać do zrealizowania te z nich, które są potrzebne (przykładowo, na liście kwot wypłacanych przez bankomat wskazać 100 złotych, a nie 50 czy 500). Instrukcja wyboru wielokrotnego jest alternatywą dla instrukcji warunkowej przydatną zwłaszcza wtedy, gdy liczba scenariuszy zaplanowanych w algorytmie jest większa niż dwa. Oczywiście, nic nie stoi na przeszkodzie, aby używać mechanizmu wielokrotnego wyboru w celu wskazania jednego z dwóch zestawów poleceń.
Omówmy przykład zastosowania wyboru wielokrotnego. Każdy użytkownik przeglądarki internetowej widział zapewne stronę WWW, na której wyświetlono kod błędu. Dzieje się tak choćby wtedy, gdy zostanie wpisany adres nieistniejącej witryny albo gdy dojdzie do zerwania połączenia z internetem. Naszkicujemy schemat obsługi różnych błędów pojawiających się podczas korzystania z przeglądarki WWW.
Pokażemy algorytm, dzięki któremu przeglądarka wyświetli komunikat o błędzie, w zależności od numeru odpowiedzi HTTPHTTP. Nie będziemy zajmować się tym, dlaczego podajemy takie, a nie inne numery błędów; ważne jest przedstawienie idei wyboru wielokrotnego.
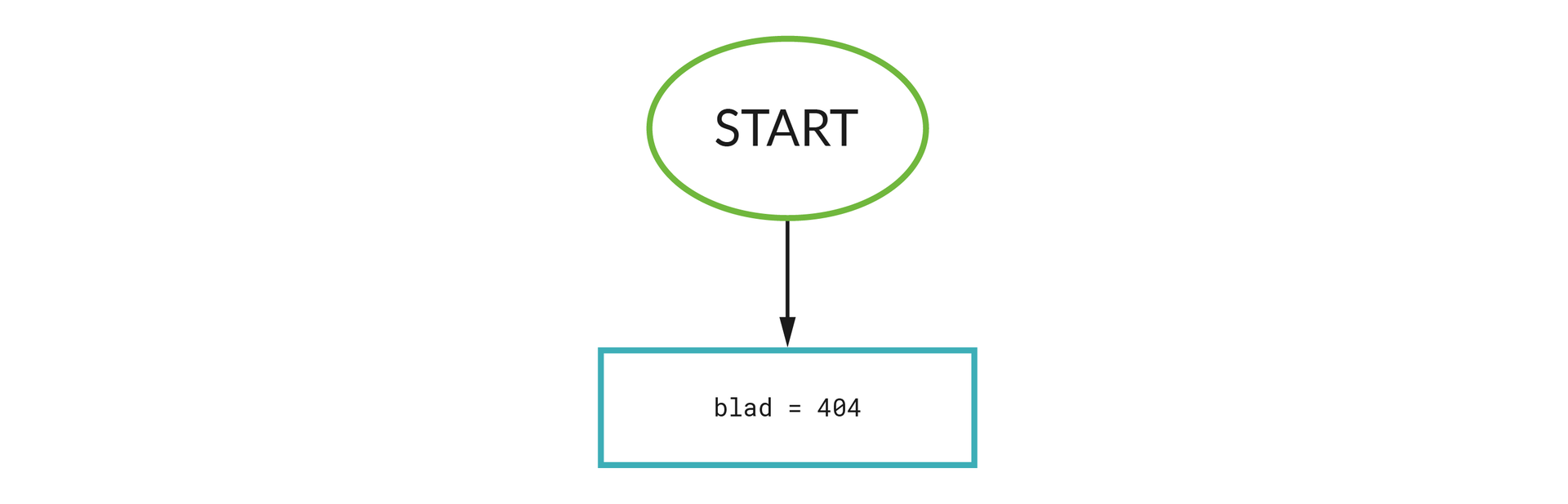
Budowanie algorytmu rozpoczynamy od utworzenia zmiennej błąd przechowującej numer błędu (przykładowo – 404):
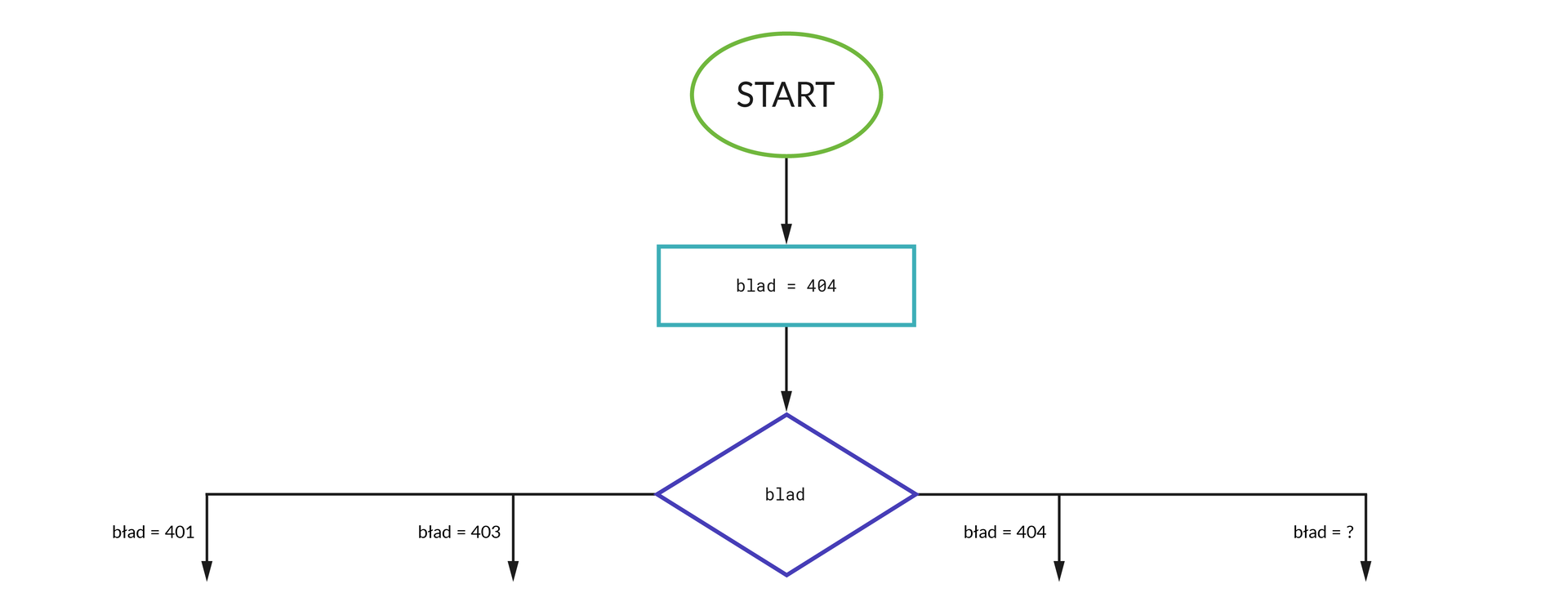
Szkicujemy konstrukcję odpowiedzialną za realizację wyboru wielokrotnego. Trzeba zaznaczyć, że jest to element niestandardowy: na liście symboli wykorzystywanych w schematach blokowych nie uwzględniono bowiem oznaczenia odpowiadającego instrukcji wielokrotnego wyboru.
Zakładamy, że chcemy obsłużyć błędy o numerach 401, 403 oraz 404. Poza tym w instrukcjach wielokrotnego wyboru definiuje się scenariusz realizowany w sytuacji, gdy żadnego innego bloku instrukcji nie można użyć (przykładowo, gdyby pojawił się błąd numer 405):
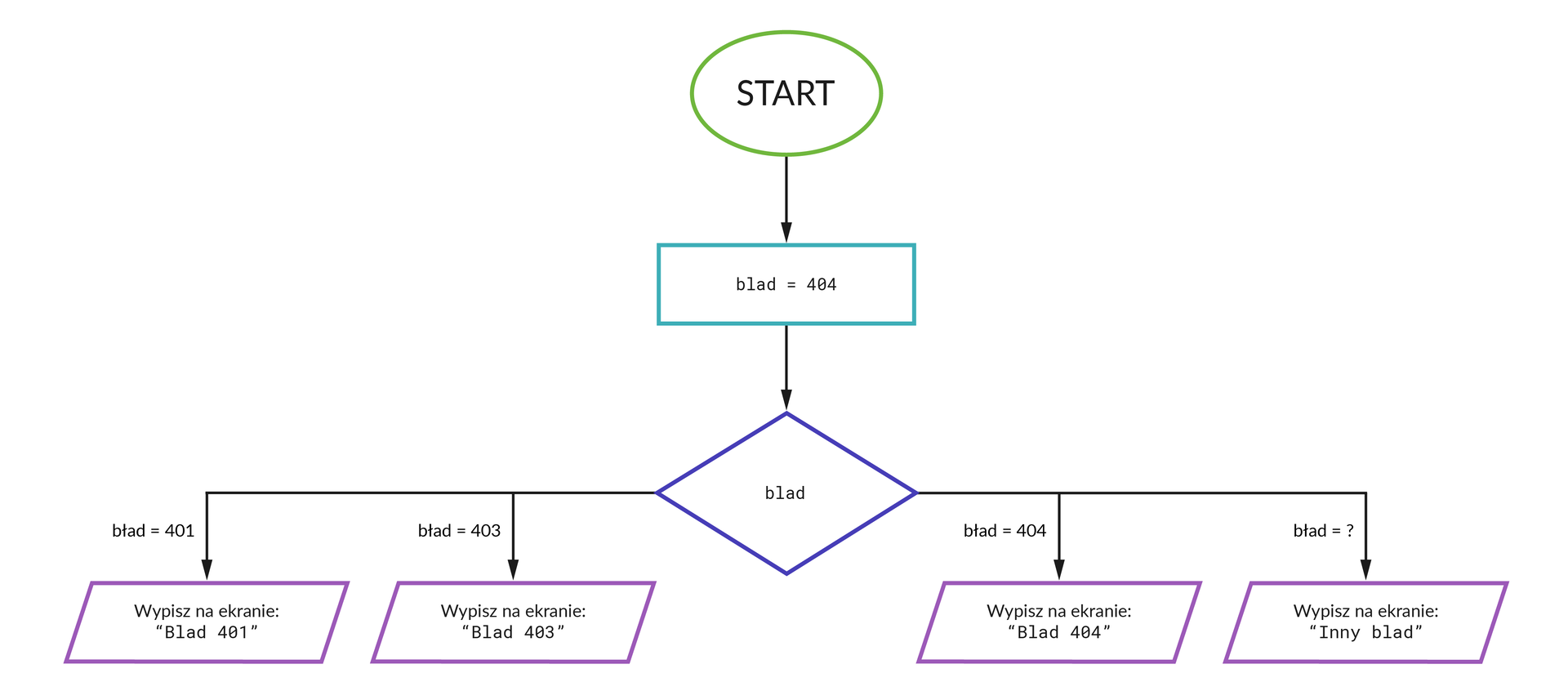
Należy zaznaczyć, że powyższy schemat blokowy jest zbudowany w uproszczony sposób. Wynika to z tego, że nie ma zdefiniowanego bloku do budowy schematów, który jednoznacznie oznaczałby wybór wielokrotny.
Należy zapisać scenariusz obsługi każdego błędu:
jeśli zmienna
błądma wartość 401, pojawia się komunikat: „Błąd 401”;jeśli zmienna
błądma wartość 403, pojawia się komunikat: „Błąd 403”;jeśli zmienna
błądma wartość 404, pojawia się komunikat: „Błąd 404”;jeśli zmienna
błądma wartość inną niż którakolwiek z poprzednich, pojawia się komunikat: „Inny błąd”.
Po opisaniu wszystkich wariantów obsługi błędu możemy zakończyć tworzenie algorytmu:
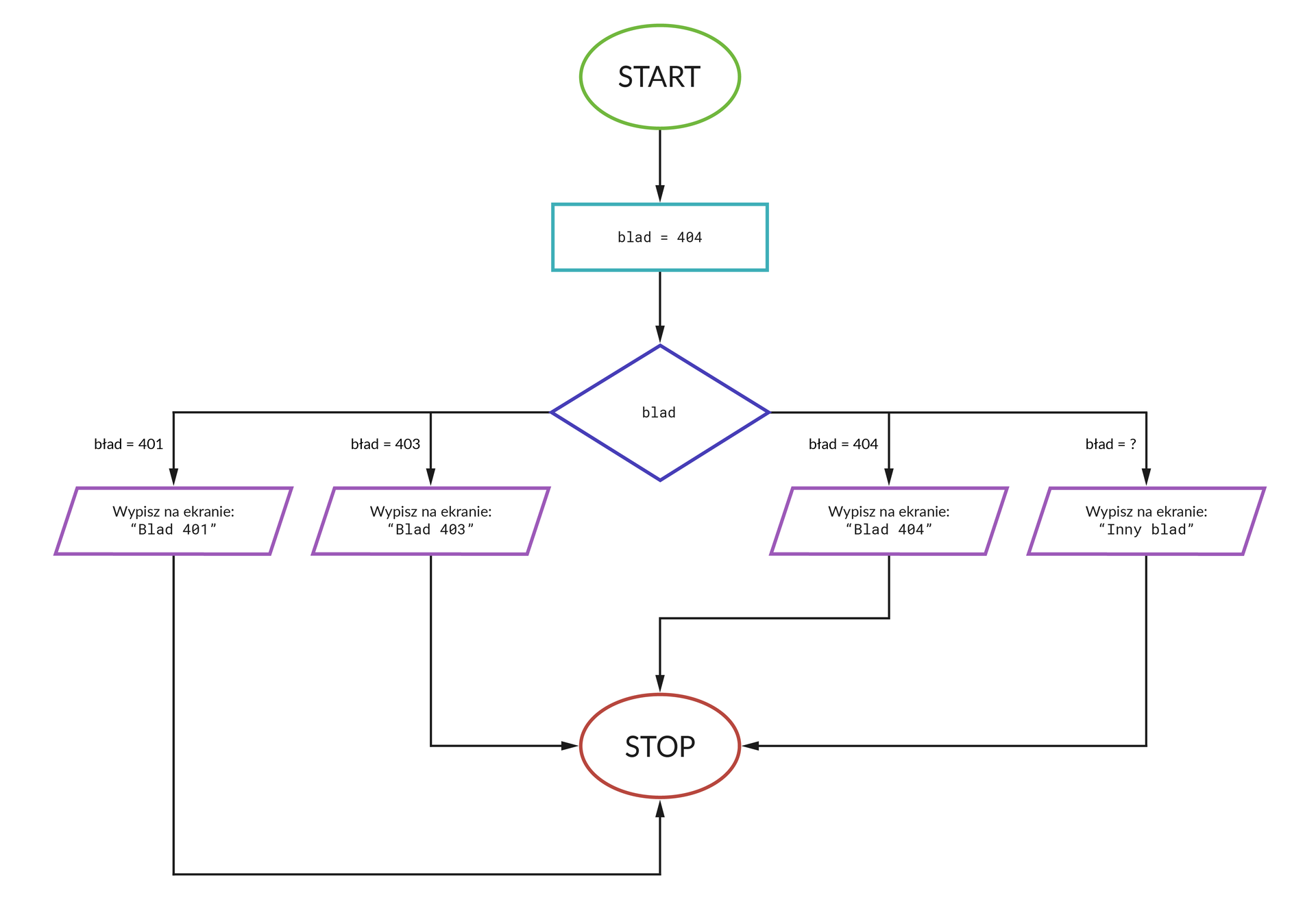
Ponieważ zmienna błąd ma wartość 404, wynikiem zastosowania algorytmu jest wyświetlenie komunikatu „Błąd 404”. Gdyby zmienna błąd miała wartość 501, pojawiłaby się informacja „Inny błąd”.
Mechanizm wyboru wielokrotnego pozwala zatem wskazać wiele wartości przyjmowanych przez zmienną błąd, odpowiednio zareagować na każdą z nich, a ponadto zapisać scenariusz dodatkowy, realizowany w przypadkach, których nie uwzględniliśmy.
Czym się różni instrukcja warunkowa od wyboru wielokrotnego?
Spróbujmy zastosować standardowe instrukcje warunkowe w celu zrealizowania zadań przedstawionych w ostatnim przykładzie. Dowiemy się, na czym polega różnica między nimi a instrukcjami wielokrotnego wyboru.
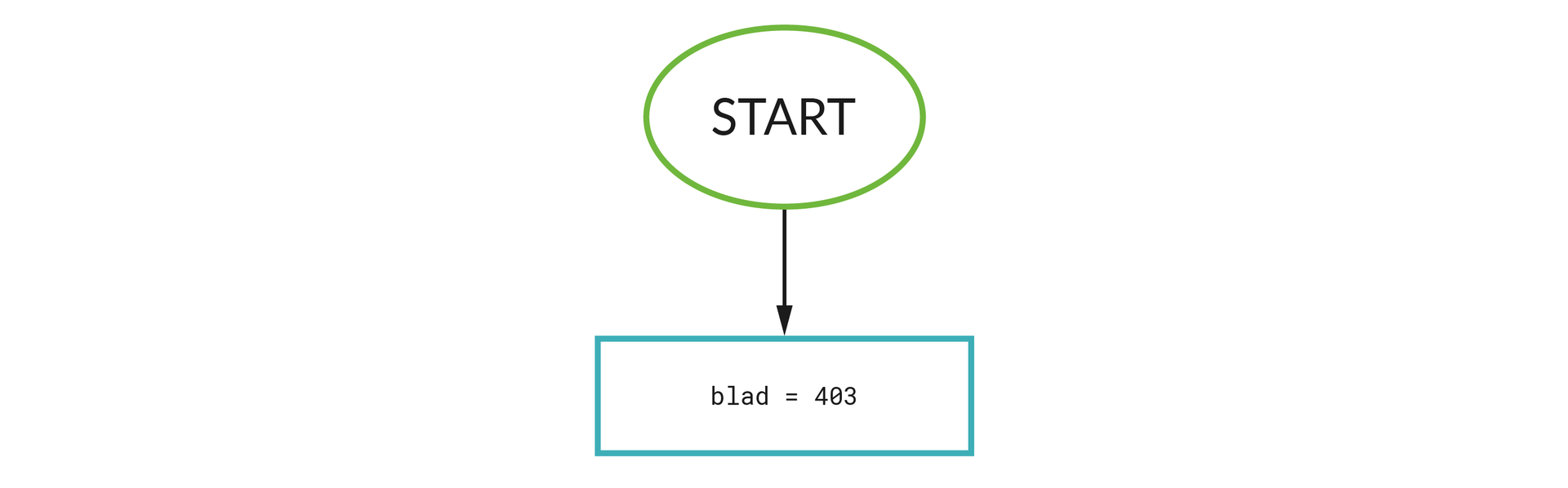
Budowanie algorytmu ponownie zaczynamy od przypisania wartości zmiennej błąd. Niech będzie to 403:
Porównujemy numer błędu z pierwszą wartością opisaną w scenariuszu (401). Jeśli obydwie liczby są sobie równe, wyświetlamy odpowiedni komunikat i zamykamy algorytm:
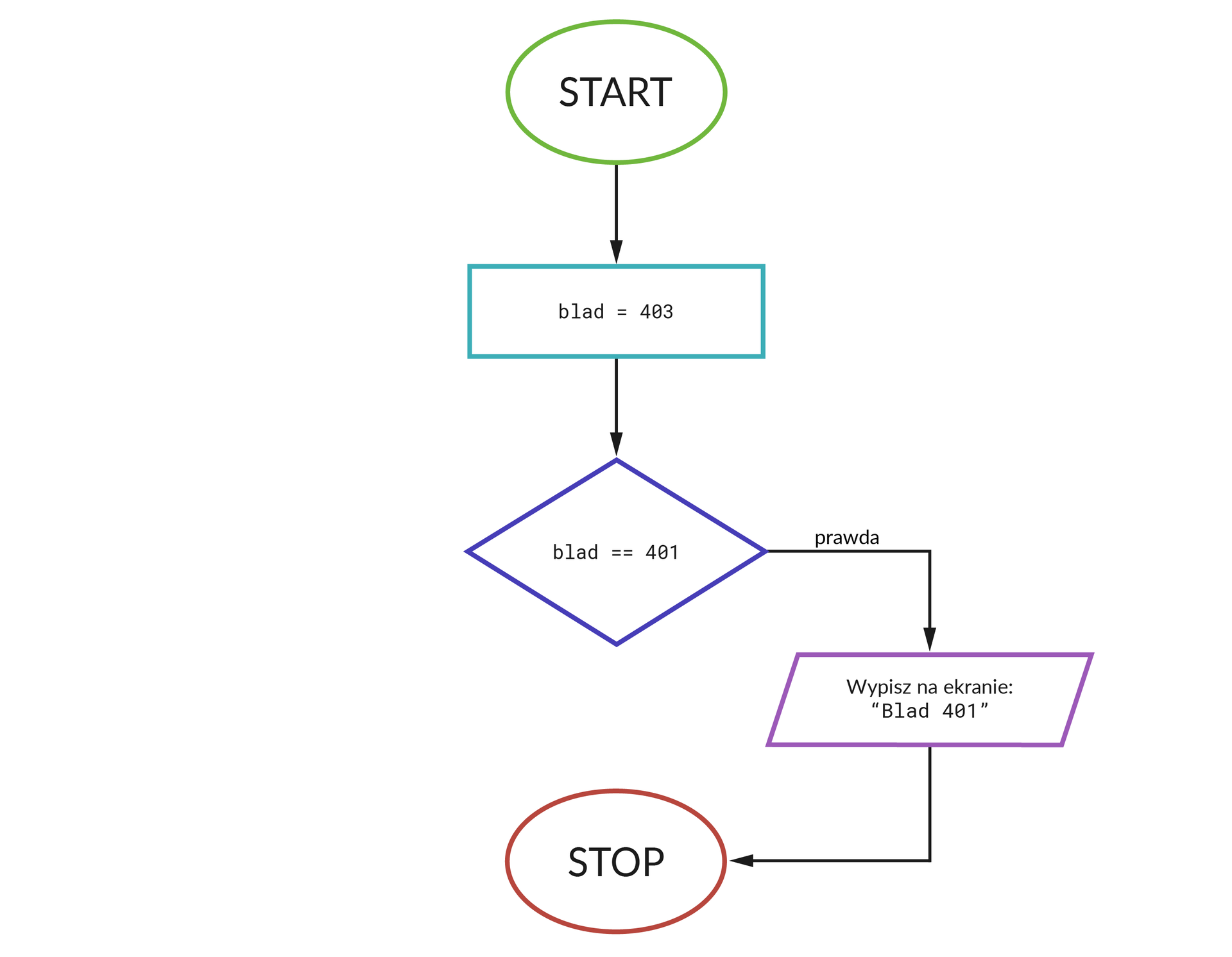
Jeśli warunek nie jest spełniony, sprawdzamy kolejną wartość (403).
Jeśli warunek jest spełniony, wypisujemy odpowiedni komunikat na ekranie i kończymy pracę:
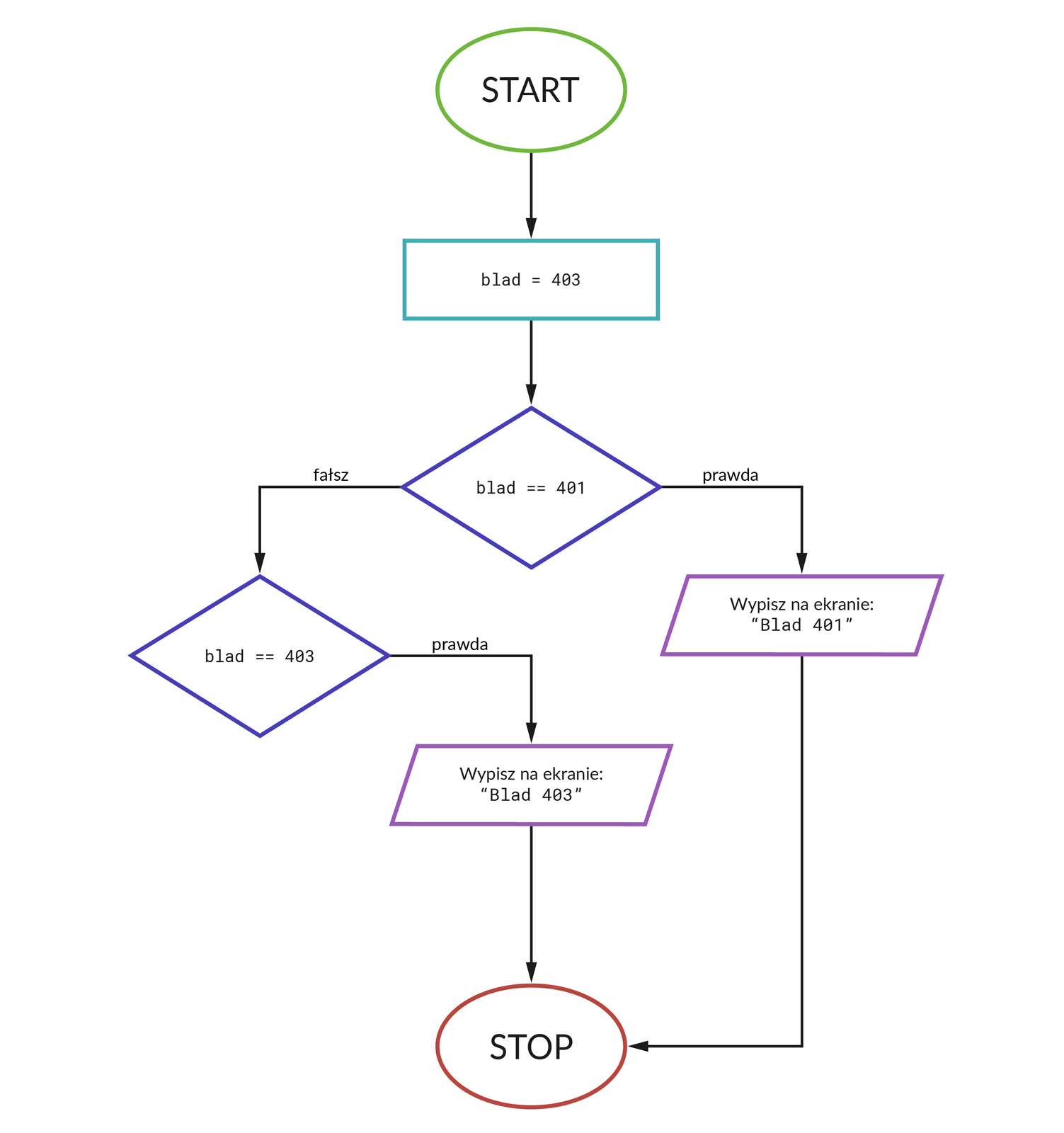
Gdyby okazało się jednak, że warunek nie jest spełniony, sprawdzamy kolejną wartość (404).
Jeśli warunek jest spełniony, wypisujemy komunikat o błędzie 404 i kończymy działanie programu. Jeśli warunek nie jest spełniony, wyświetlamy informację o pojawieniu się innego błędu i kończymy pracę:

Nietrudno zauważyć, że zastosowanie instrukcji warunkowej znacząco komplikuje algorytm. Instrukcja wyboru wielokrotnego przyczynia się do uproszczenia kodu, choć rezultat jest taki sam.
Słownik
zbiór zasad, według których wymienia się dokumenty hipertekstowe między programami w sieciach komputerowych bazujących na architekturze klient‑serwer (przykładowo, między przeglądarką WWW a serwerem); standardowo wykorzystuje port 80