Przeczytaj
Tabela kodu genetycznego
Rozszyfrowanie kodu genetycznegokodu genetycznego przez amerykańskich biochemików Marshalla W. Nirenberga, Roberta W. Holleya i Hara Gobinda Khorana pozwoliło stworzyć tabelę kodu genetycznego – umożliwia ona odczytanie sekwencji białka powstającego na podstawie mRNA. A także na podstawie sekwencji aminokwasów w białku można określić kolejność nukleotydów w kodującym go genie. Istnieją dwie podstawowe formy tabeli kodu genetycznego: kwadratowa oraz kolista.
Więcej informacji na temat kodu genetycznego możesz znaleźć w materiale: Cechy kodu genetycznegoCechy kodu genetycznego.
Kwadratowa tabela kodu genetycznego
Kwadratowa tabela kodu genetycznego składa się z poziomych i pionowych kolumn. Odczytywanie zaczyna się zawsze od lewej strony, w pozycji „1 nukleotyd”. Występują tu cztery wiersze oznaczone: U (uracyl), C (cytozyna), A (adenina), G (guanina) – są to pierwsze litery kodonukodonu odpowiadającego za dany aminokwas.
Drugi nukleotyd w kodonie znajduje się w górnej osi tabeli, oznaczonej jako „2 nukleotyd”. Wiersze z kolumny „1 nukleotyd” przecinają się z kolumnami zawierającymi drugi nukleotyd uszeregowanymi w kolejności: U, C, A, G, tworząc duży kwadrat z czterema różnymi sekwencjami.
Trzeci nukleotyd odczytywany jest z kolumny „3 nukleotyd”, gdzie nukleotydy ułożone są w kolejności U, C, A, G. Znalezienie trzeciego nukleotydu pozwala na skompletowanie wszystkich nukleotydów w kodonie i odczytanie przypisanego do danego kodonu aminokwasu bądź też sygnału START (dla kodonu AUG) lub STOP (dla kodonów UAA, UGA, UAG).
1 nukleotyd | 2 nukleotyd | 3 nukleotyd | |||||||
U | C | A | G | ||||||
U | UUU | (Phe/F) fenyloalanina | UCU | (Ser/S) seryna | UAU | (Tyr/Y) tyrozyna | UGU | (Cys/C) cysteina | U |
UUC | UCC | UAC | UGC | C | |||||
UUA | (Leu/L) leucyna | UCA | UAA | STOP | UGA | STOP | A | ||
UUG | UCG | UAG | STOP | UGG | (Trp/W) tryptofan | G | |||
C | CUU | CCU | (Pro/P) prolina | CAU | (His/H) histydyna | CGU | (Arg/R) arginina | U | |
CUC | CCC | CAC | CGC | C | |||||
CUA | CCA | CAA | (Gln/Q) glutamina | CGA | A | ||||
CUG | CCG | CAG | CGG | G | |||||
A | AUU | (Ile/I) izoleucyna | ACU | (Thr/T) treonina | AAU | (Asn/N) asparagina | AGU | (Ser/S) seryna | U |
AUC | ACC | AAC | AGC | C | |||||
AUA | ACA | AAA | (Lys/K) lizyna | AGA | (Arg/R) arginina | A | |||
AUG | (Met/M) metionina | ACG | AAG | AGG | G | ||||
G | GUU | (Val/V) walina | GCU | (Ala/A) alanina | GAU | (Asp/D) kwas asparaginowy | GGU | (Gly/G) glicyna | U |
GUC | GCC | GAC | GGC | C | |||||
GUA | GCA | GAA | (Glu/E) kwas glutaminowy | GGA | A | ||||
GUG | GCG | GAG | GGG | G | |||||
W biologii i genetyce wykorzystuje się trzyliterowe i jednoliterowe nazwy skrótowe aminokwasów, które ułatwiają np. zapisanie całej sekwencji łańcucha polipeptydowego. Skróty te występują także w tabeli kodu genetycznego. Na przykład alanina może być zapisana w skrócie jako Ala lub A, a arginina jako Arg lub R.
Kolista tabela kodu genetycznego
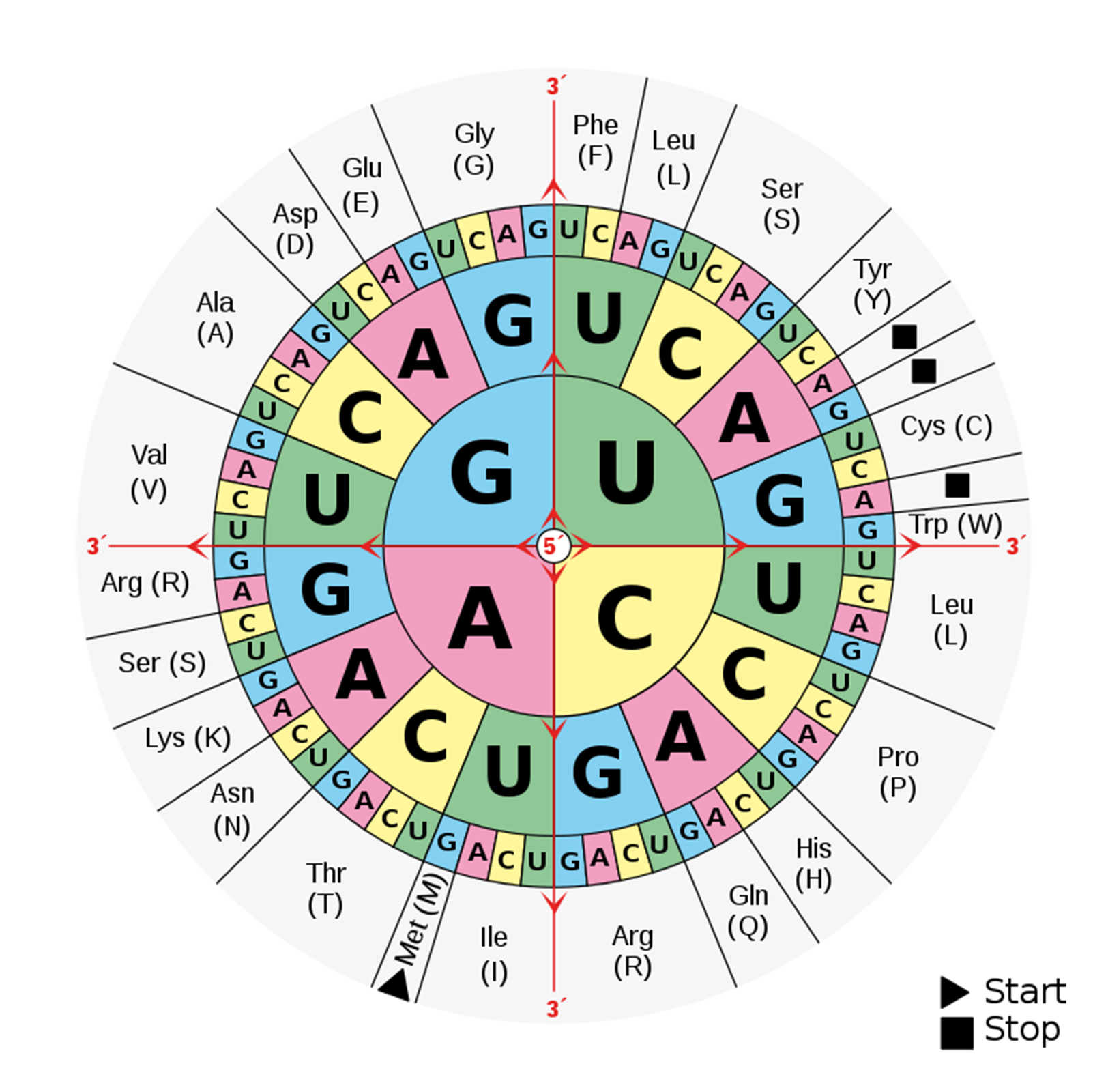
Tabela kodu genetycznego w postaci koła ilustruje wszystkie możliwe kombinacje w kodonie oraz przypisane im aminokwasy. Cała struktura podzielona jest na cztery ćwiartki i zawiera cztery pierścienie współśrodkowe. Trzy pierścienie (zaczynając od środka) zawierają symbole nukleotydów, a czwarty pierścień zawiera symbole aminokwasów.
Kolistą tabelę kodu genetycznego odczytuje się od najbardziej wewnętrznego pierścienia, w którym znajdują się cztery nukleotydy: G, U, A i C. Kolejnym krokiem jest odczytanie drugiego nukleotydu w kodonie, umieszczonego na drugim pierścieniu. Do każdego pierwszego nukleotydu można dopasować jeden z czterech nukleotydów, ułożonych w kolejności: U, C, A, G. Trzeci nukleotyd odczytywany jest z najbardziej zewnętrznego pierścienia koła zawierającego nukleotydy. Do drugiego nukleotydu w kodonie można dopasować także jeden z czterech nukleotydów uszeregowanych w takiej kolejności jak nukleotydy w poprzednim pierścieniu. Aby ułatwić odczytywanie kolejnych nukleotydów kodonu zostały one zapisane czcionką o różnej wielkości: od największej przy nukleotydzie pierwszym do najmniejszej dla ostatniego nukleotydu z kodonu.
Dodatkowym ułatwieniem jest oznakowanie nukleotydów kolorami, co ułatwia szybką lokalizację nukleotydów, zwłaszcza w pozycji trzeciej.
Każdemu z 61 kodonów (trójek nukleotydów) przyporządkowano jeden aminokwas, którego symbol lub nazwę umieszczono na ostatnim, zewnętrznym pierścieniu koła. Trzy kodony to nonsensowne kodony STOP.
Kodon START oznaczony jest jako trójkąt, opatrzony także opisem „Met (M)”, ponieważ koduje aminokwas metioninę. Jest on pierwszym z aminokwasów w tworzonej sekwencji białka. Trzy z kodonów oznaczono za pomocą kwadratów. Są to kodony STOP i nie mają one przypisanych aminokwasów, gdyż stanowią sygnał dla rozpadu maszynerii translacyjnejtranslacyjnej, poprzez przyłączenie czynnika uwalniającego zamiast aminokwasu.
Odczytywanie kodonów na mRNA podczas translacjitranslacji rozpoczyna się od zlokalizowania kodonu START. Na podstawie kolejnych kodonów są dołączane odpowiednie aminokwasy. Synteza białka trwa do odczytania kodonu STOP. Odczytywanie kodonów w mRNA odbywa się od końca 5′ do końca 3′, które warunkują kolejność aminokwasów w polipeptydzie od N‑końca pierwszego aminokwasu (metioniny) do C‑końca ostatniego. Koniec N polipeptydu stanowi aminokwas z wolną grupą aminową, a koniec C – aminokwas z wolną grupą karboksylową.
Słownik
sposób zapisania informacji genetycznej (w postaci sekwencji nukleotydowej) o kolejności aminokwasów (sekwencji aminokwasowej) w cząsteczkach białek
sekwencja trzech nukleotydów występująca w DNA lub w mRNA, stanowiąca jednostkę kodującą określony aminokwas podczas syntezy białka; istnieją 64 kodony, z czego 61 to kodony określające 20 podstawowych aminokwasów białkowych, natomiast 3 pozostałe odpowiadają za zakończenie translacji
(łac. transcriptio – przepisywanie) proces syntezy RNA, podczas którego na matrycy DNA syntetyzowana jest komplementarna nić mRNA
proces biosyntezy białka, podczas którego, na podstawie informacji zapisanej w nici mRNA, syntetyzowany jest polipeptyd